我需要使用一个mini的反汇编引擎嵌入我的C项目中,能够做简单的指令分析工作,帮我区分操作码和数据。发现国外大佬写的Hacker_disassembler_engine很满足我的需求,但是奈何我看不懂啊,不得不学习一下intel的opcode,于是有了下文。
intel机器码
intel的指令体系为复杂指令系统(CISC),它这里的复杂绝非浪得虚名,由于以往的机器上内存是个很昂贵的设备,因此,intel的指令编码尽可能地利用了每一个bit,再加上兼容性的考虑,使得整个intel指令结构异常复杂。
物理上,CPU的逻辑运算单元只操作计算机中的两个对象:寄存器和内存。除了这两个操作对象之外,还有一种对象,那就是立即数(immediate),物理上指令执行时,这个数字是在CPU中的,也就是CPU取得的指令中,这个数就已经在那里了。所有的指令编码都是围绕着这三个操作对象进行的,不同的是立即数不需要去找,寄存器简单的编码就行了,而内存不但需要指出其位置,还要指出其大小。此外,还有一些辅助的操作说明,比如是否重复一些操作等等。
intel指令格式
看一下intel的确切的指令格式:
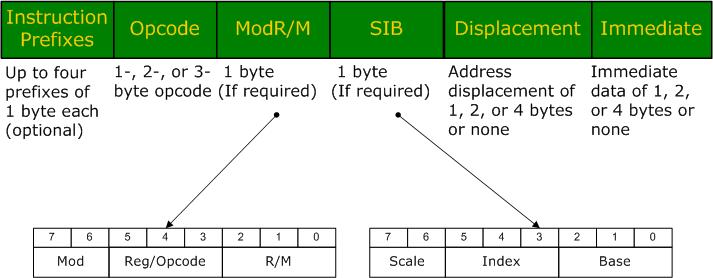
prefix部分是指令操作的一些辅助说明,opcode编码了进行什么样的操作,跟汇编格式里面的mnemonic对应,CPU知道了什么操作之后就会寻找操作的对象,是寄存器还是内存?ModR/M部分就给出了操作的对象,R是register,M是memory,而Mod指示了到底是寄存器还是内存。如果ModR/M的字节数足够大的话,那么或许就不需要后面的两个部分了,实际上ModR/M只有一个字节,能编码所有的寄存器,却不能编码所有的内存寻址模式,intel使用后面两个部分来辅助ModR/M完成确切的内存定位SIB和displacement。寻址方式跟CPU对内存的管理密切相关,intel的寻址方式很多,但全部都编码到了SIB和displacement之中。但是需要注意一个OpCode不只对应一个mnemonic,一个mnemonic不只对应一个OpCode。
定长指令
定长指令(指的是一个Opcode对应的指令长度是一定的),其对应的汇编指令格式是固定的(比如0X40不能加立即数和偏移量就只能表示inc eax;而B0只能加一个字节的立即数指令长度为2字节,B0 XX即为mov al,XX不能能表示其他任何指令),但不管是定长还是不定长的硬编码,其都可以从下面的Opcode Map表(TableA-2和TableA-3)中找查出来(红色圈出来的是比较重要的以及我们要分析的定长指令):
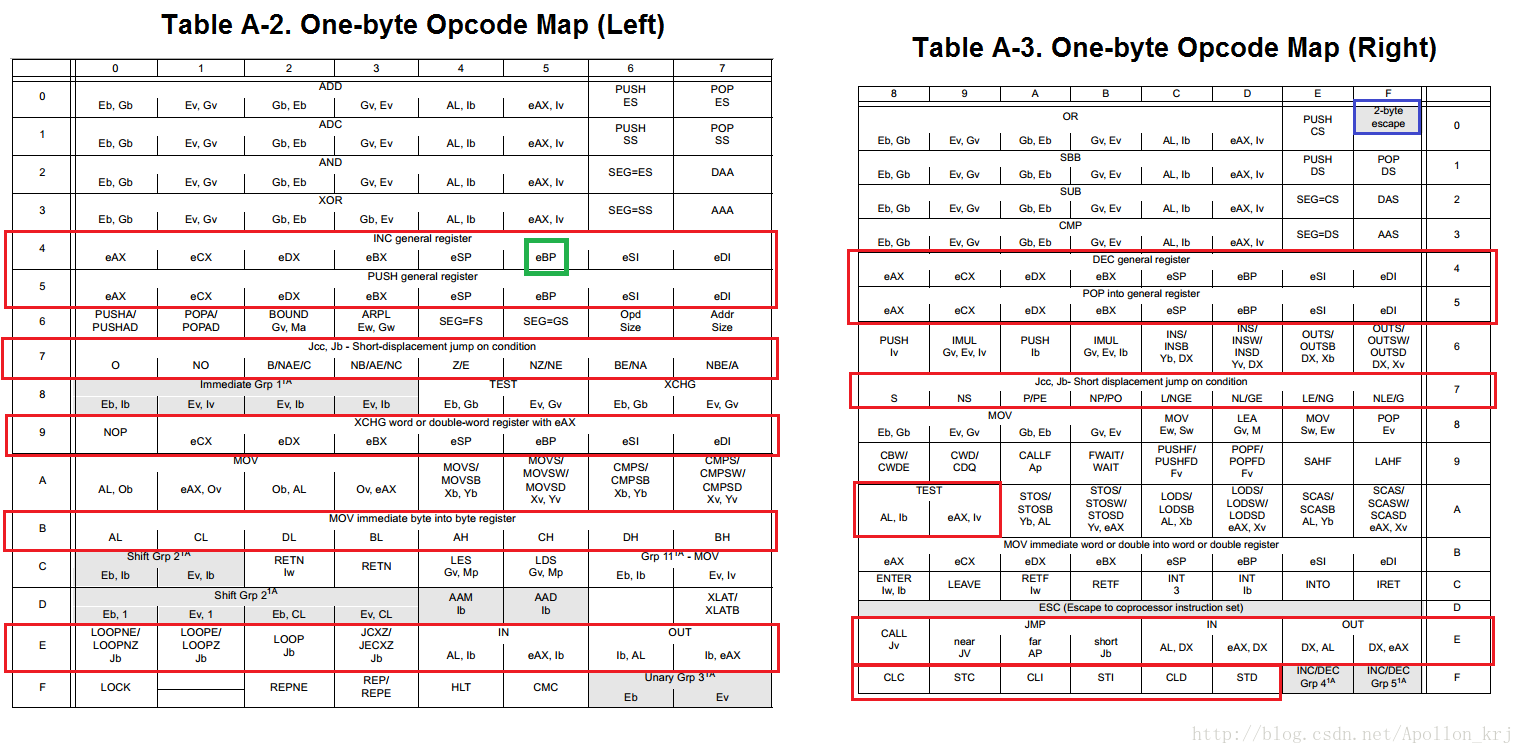
一个1Byte的定长指令,其16进制为类似于“AB”的形式,而第一个A是Opcode Map表中的行号,第二个的B是其列号,行号和列号就能确定一个具体的指令。比如:第4行第5列索引出来的指令为(绿色圈出来):inc ebp,第5行第0列为push eax等等。
但是由于指令的Opcode部分不止有一个字节的,还有两个字节的,那么两个字节的仅仅用该表是无法表示的,设计人员在设计时,留了一个特殊的位置即0F,0F作为两字节指令的第一字节,而第二字节再另外一张表中。也就是说所有两字节的指令都是以0F开头的(注意:这里说的两字节都是仅仅指Opcode的长度)。而另外一张表(TableA-4与TableA-5)如下所示:
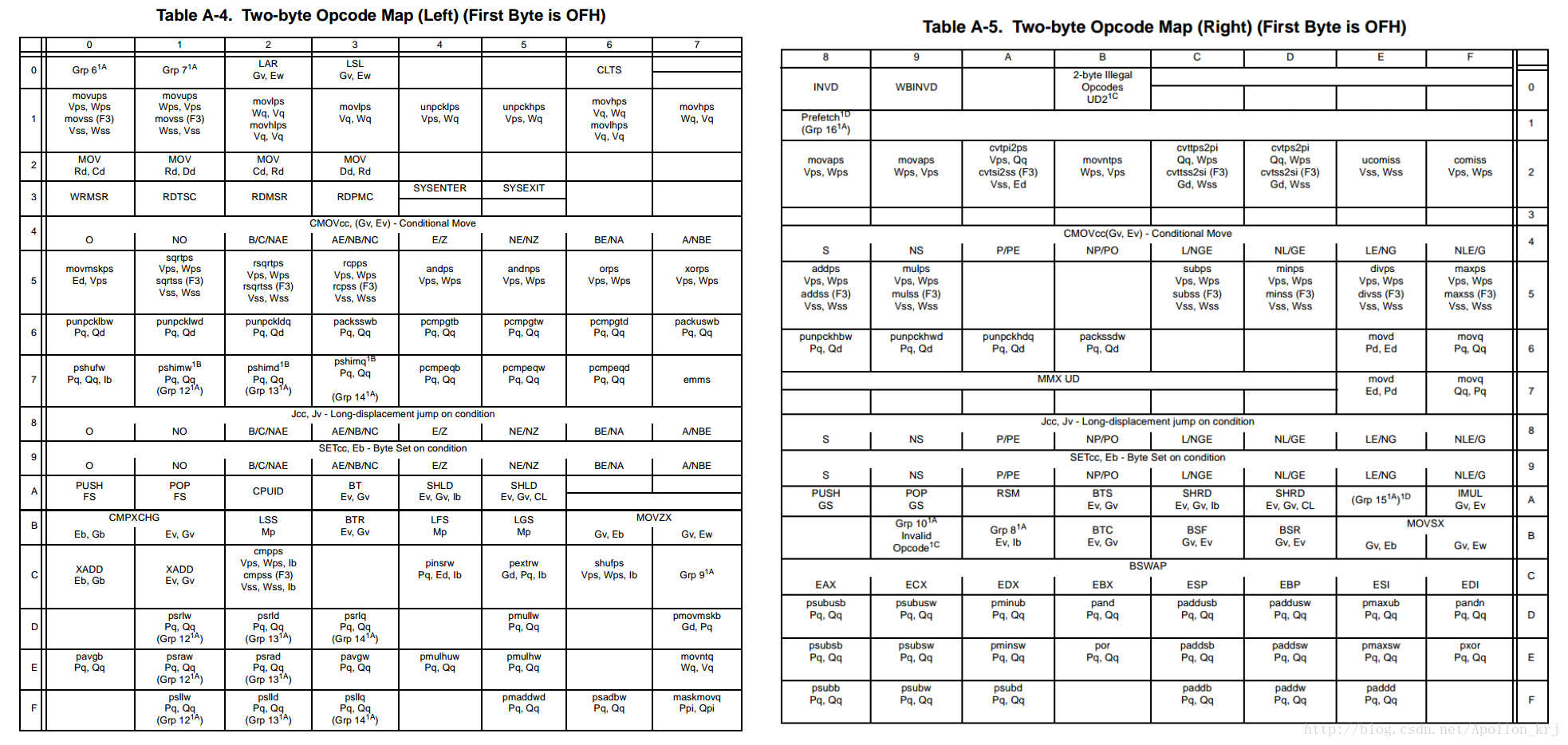
来看几个一字节的指令,看一下规律:
1 | 50 <–> push eax |
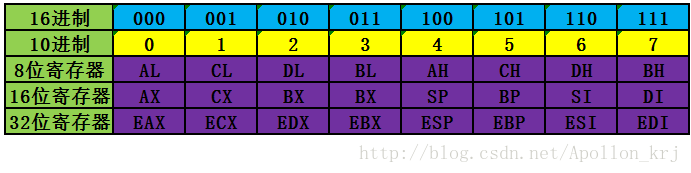
这里可以发现一个规律,都是寄存器跟编号之间有一定的对应关系,比如0对对应eax,寄存器编号如下所示。
修改EIP并且与JCC对应的定长指令
硬编码中的Opcode后面的立即数并非是跳转的地址,跳转地址=当前指令地址+当前指令长度+imm
近距离JCC跳转
条件跳转:Opcode后面跟一个立即数的偏移,因此指令共两个字节(跳转地址只占有一个字节)
立即数是有符号的:最高位为0(7F)向下跳,最高位为1(80)向上跳
1 | 70 <–> JO(O标志位为1跳转) |
0F80~0F8F远距离JCC跳转
后面跟一个四字节的立即数,指令长共6字节80000000~7fffffff。
其他修改EIP的指令
同JCC指令的硬编码一样,其硬编码中Opcode后面的立即数也不是要跳转的地址,计算方式同JCC相同:跳转地址=当前指令地址+当前指令长度+imm。
与ECX相关的跳转指令(循环指令)
1 | E0 <–> loopne/loopnz Ib(dec ecx) (ZF=0 && ECX != 0) |
测试如下:

直接CALL与间接CALL
所谓直接call即编译时确定地址,间接call即地址存在内存中,并且在内存中的地址也是运行时才确定。
1 | E8 <–> call Id |
E8call为直接call,call后面的地址即为要跳转的地址,FFcall为间接call,后面跟的内存那只能够存放着即将要跳转的地址。比如用对象指针访问一个普通成员函数和一个虚函数,其call的硬编码都不同:
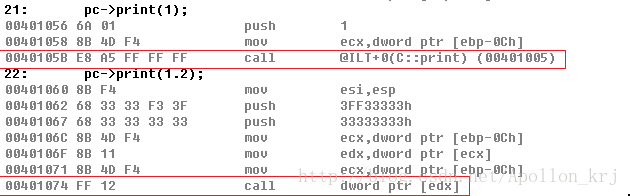
ret和retf
1 | C3 <–>ret (pop eip) |
指令前缀
我们在上面提过,修改寄存器的指令中不存在16位寄存器修改的硬编码。而这些与16位寄存器相关的编码是通过加上指令前缀(Instruction Prefixes)的方式来实现的,有指令前缀则原本的32位寄存器操作指令,就会变为16位寄存器操作指令来用,不仅是定长指令如此,不定长指令也是如此。但指令前缀不仅能进行16位32位寄存器操作硬编码转换,我们一一来看几种常用的指令前缀:
段前缀
首先在32位汇编中,8个段寄存器:ES、CS、SS、DS、FS、GS、LDTR、TR(顺序固定),不再用段寄存器寻址而只做权限控制。段寄存器其实是个结构体,共96位,用汇编指令只能访问其中16位。
1 | 2E - CS |

其中8925是Opcode,而不同的指令前缀代表了不同的段寄存器。
1 | 注意:如果没有特殊说明即没有人为指定段前缀,且中括号里面有寄存器的时候有如下约定: |
操作指令前缀:修改默认长度
这个即所谓指令前缀解决无16位寄存器操作指令的问题:0X66前缀修饰Opcode,则修正32位长度为16位:
如下所示(无论定长指令50还是不定长指令89均相同):

操作指令前缀:修改默认寻址方式
0X67作为前缀修改操作数宽度(将硬编码默认对应的操作数宽度改为16位)
如下所示(操作指令前缀将寻址方式按16位汇编的寻址方式进行寻址):

同一Opcode因为有无指令前缀而长度不同,因此加上指令前缀前后相当于Opcode的指令长度也是不定的,但是这些“不定长”可预见的。有前缀则指令长度加一。而真正的不定长指令却不是如此的。
不定长指令
ModR/M
首先来看几条指令的通用公式
1 | 88 <–>mov Eb,Gb |
这些指令都是可以从opcode map中查到的。
对几个关键词做如下解释:
1 | G:通用寄存器 |
指令长度常规情况分析
如果确定是不定长指令,则其后必定存在一个字节的ModR/M,而ModR/M的bit信息指出了通用形式的不定长指令的具体形式,ModR/M的格式如下所示:
1 | +------+-------+--------+ |
其中第3、4、5位三位即Reg/Opcode来确定是哪一个通用寄存器G,(暂时仅考虑Reg/Opcode中reg的情况);
其它两部分来确定E是什么(R/M)以及具体细节。
(Mod值有0-3四种情况、Reg/Opcode和R/M有0-7八种情况;Mod的00~10是内存,11是寄存器;R/M与Reg/Opcode的值即为寄存器的编号:eax/ax/al编号0、ecx/cx/cl编号为1…)
我们拿一条指令来具体分析:
1 | 测试一:"88 01 02 03 04 05 06 …" |
1 | 测试二:89 01 …(以32位CPU为准) |
以上计算步骤归结为一张表:

该表分为五大块:寄存器编号部分的最上面一块,以及以Mod分界的下面的四块。用ModR/M解析出来的Reg/Opcode去第一块中查具体寄存器;以Mod和R/M去查Mod块中具体的某一行,最后再合并查到的各部分得到汇编指令。
1 | 测试三:8A 82 12 34 56 78 |
非常规情况分析
有一种特殊情况就是Mod=00且R/M=101时的情况(对应的ModR/M的值由05、0D、15、1D、25、2D、35、3D八种具体情况),这些情况只需要将原来的ebp换成一个disp32即可(该数即机器指令中紧接着ModR/M后面的四个字节)。这其实也是不需要其它辅助性工作就能解析出来的,测试如下:

ModR/M中的特殊情况与SIB引出
红框框出来的内容,仅仅依靠Table2-2一张表是无法解析出来的。还需要SIB和另外一张表(SIB的解析步骤归结的一张表)才能够解析的,Table2-2的Notes部分也提到了这张表Table2-3:
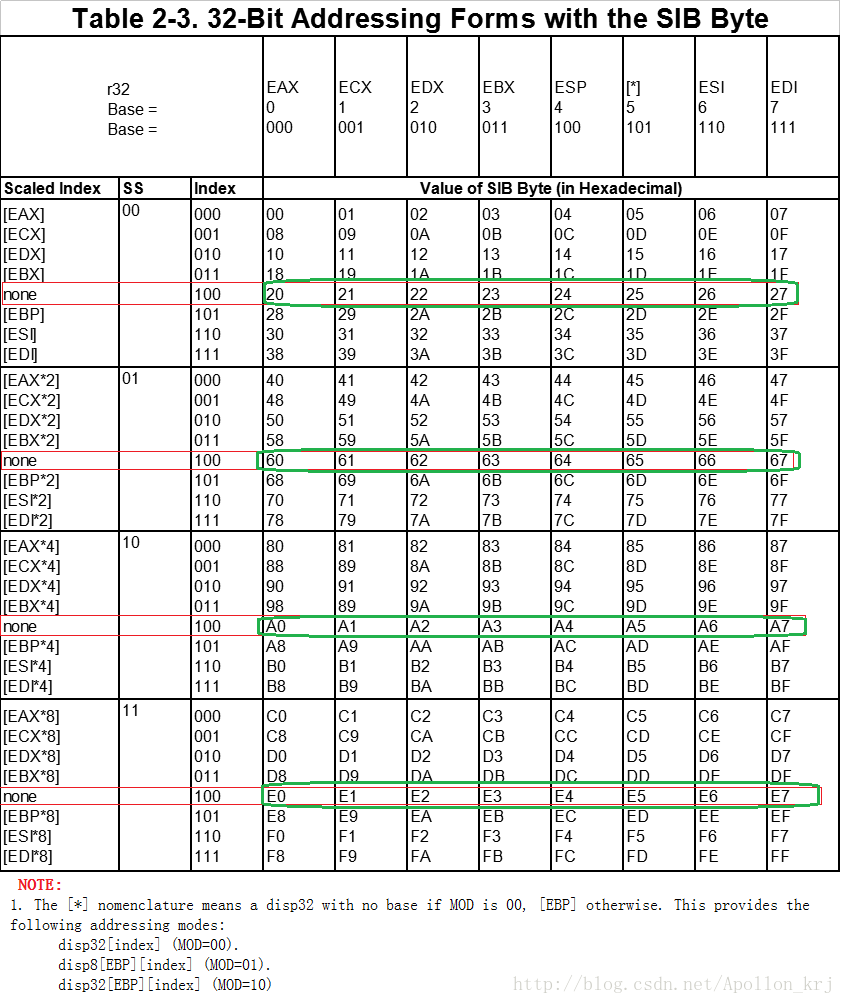
我们先来分析该表的一般情况:该表是根据SIB的bit信息来索引查看的,SIB是紧接着ModR/M的一个字节。不定长指令后必有ModR/M,而ModR/M的Mod不为”11”且R/M值为”100”(ESP)时则ModR/M后就有SIB。
我们先来看SIB的格式与解析方式:
1 | +------+------------+--------+ |
该三部分均存在于[]的括号中,格式为:Base + Index2^(Scale),Base为寄存器编号索引的寄存器,Index也是寄存器编号索引的寄存器,Scale为00~11,因此格式又为:Base + Index * 1/2/4/8所以格式形如:ds:[eax+ecx4]。
1 | 解析"88 84 48 12 34 56 78": |
看一个例子:
1 | 00162560 > 888448 12345678 mov byte ptr ds:[eax+ecx*2+0x78563412],al |
SIB中的特殊情况
其实就只有一种情况需要特别对待,我们知道[–][–]两部分分别为:[Base]和[Index * 2^(Scale) ]。若index == 100(ESP)则[Index * 2^(Scale)]部分不存在。
index 等于100(SIB = 64/65),base等于101与(65)否(64),结果都一样(index都不存在):
1 | 00162560 > 889C64 12345678 mov byte ptr ss:[esp+0x78563412],bl |
HDE反汇编结构体的理解
其实有了上面的预备知识,HDE中表示指令的结构体就容易完全理解了:
1 | typedef struct { |
英文的注释还是不太明白,下面详细说一下每个字段的含义:
1 | len : 当前指令的长度 |
下面用一个包含modR/M,sib这样的变长指令做一个测试:
1 | unsigned char code[] = { 0x88,0x84,0x48,0x12,0x34,0x56,0x78}; |
可以得到结构体如下:
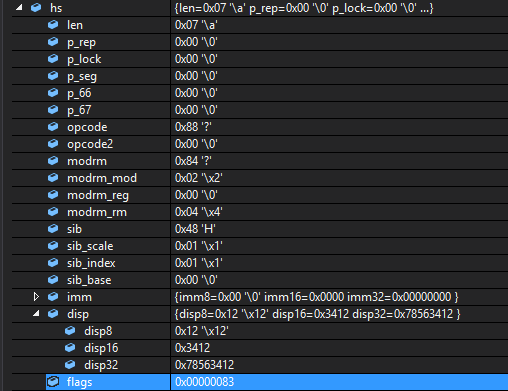
这下舒服多了,终于看懂了。。。。
参考
http://read.pudn.com/downloads128/ebook/543578/OpCode.pdf
https://blog.csdn.net/Apollon_krj/article/details/77508073
https://blog.csdn.net/Apollon_krj/article/details/77524601