原文地址: https://www.gdatasoftware.com/blog/2022/06/37445-malware-detection-is-hard
前言
科研人员开发的人工智能检测引擎具有98% 的恶意软件检测率和5% 的假阳性率。如果您认为这是一种非常好的防病毒软件技术,那么本文可能会改变您的想法。
恶意软件检测不能被彻底解决,但是并不是不切实际的
Fred Cohen 在 1984 年已经证明了病毒检测是一个不可解问题。他假设存在一个完美的病毒检测程序是存在的,然后他构造了一个潜在的病毒,它仅在完美的检测程序认为它是干净的时才有感染性,所以这个完美的检测程序不能提供正确的检测结果,所以这个并不是一个完美的病毒检测程序。由于所有病毒都是恶意软件,因此可以为恶意软件检测构造类似的反证法证明这个完美的恶意代码检测程序是不存在的。
但是,在数学意义上的”不可解”并不意味着它没有实际的解决方案。一个不可解问题是不能在所有情况下提供正确的答案的决策问题。因此,如果您有一个程序,可以正确回答 99.9999% 的情况,但是 0.0001% 的情况回答错误,那么这个问题可能同时是不可解的和仍然实际可行的。我们已经有足够的解决方案来解决类似的问题。一个例子是旅行商问题,它在物流的包裹路由系统或电路制造过程中具有应用。尽管尚未发现任何可以在合理时间内解决旅行商问题的算法(它是 NP-hard),但有足够的近似解决方案来计算包裹递送的路线。
同样适用于防病毒产品,它们尽可能最好地保护系统免受恶意软件的攻击。但是与包裹收件人不同,恶意软件开发人员正在积极试图以使防病毒产品做错决策并不检测这些程序的方式创建恶意软件。这类似于人们故意和不断试图找到包裹交付路由输入,这些输入在合理时间内没有得到最佳解决。
因此,恶意软件检测具有困难的本质,并需要不断的工作和改进以保持有用。然而,防病毒程序因被视为过时的、不灵活的而被诟病。事实真的是这样吗?
有人说他们可以做的更好
从媒体和广告商的常见声明中,人们得出的印象是防病毒产品故意使用过时的技术,并拒绝利用已经研究过的那些新的人工智能和其他技术来建立他们的系统。我们经常看到像”传统的防病毒已经死了”和”这个人工智能比防病毒更好”这样的文章吗?
这引出了一个问题:如果防病毒产品很容易就能更好,为什么它们不适应新技术呢?事实是:
- 他们的确这么做了;
- 它们不能承受误报,并且与可以承受误报的应用程序进行了不公平的比较。
谬论1: 防病毒产品使用过时的技术
据媒体报道,防病毒产品搜索文件中的特征码以及将文件哈希值与阻止列表进行比较这样的技术进行检测恶意代码。这些检测机制仍然存在,但防病毒产品已经使用其他恶意软件检测技术至少20年了。

2021 年的文章声称,防毒软件仅仅依赖于病毒签名来检测已知威胁。但是这是错误的:防毒软件不仅仅依赖于病毒签名,并且病毒签名不仅仅可以检测已知的恶意软件。

有文章声称下一代的解决方案比当前的杀软更好。

这篇文章错误地假设签名仅检测已知的恶意软件,可能是因为他将签名与基于模式的检测方法等效。
当我对恶意软件分析产生兴趣时,我读到的第一本关于这个主题的书是Péter Szőr的《The Art of Computer Virus Research and Defense》(2005年)[szor05]。这本现在已经有17年历史的书描述了远远超出模式签名和散列值的方法。Szőr提到了仿真,X射线扫描,内存扫描,基于算法的签名,行为阻止器和网络扫描[szor05]等。这些技术在过去几年中得到了改进,并开发了新的技术。
人工智能(AI)技术在Szőr的书中没有提到,但该技术已经有一些年头了。它们服务于许多目的,包括恶意软件聚类,客户端系统上的恶意软件检测以及自动签名创建。GDATA的DeepRay从2018年开始,我们当然不是第一家使用AI来增强检测能力的AV制造商。
尽管有了所有这些进展,这个谬论仍然存在。我可以想到两个原因:
首先,安全产品营销积极地强化它,以给人一种广告产品是新的、更好的印象。NextGen防病毒产品就是这样一个例子。他们声称拥有新的、不同的检测和保护技术,但他们使用的是与存在时间更长的防病毒产品相同的技术。反恶意软件和防病毒软件之间的人为区分也在尝试着同样的做法,给人一种(错误的)印象,即防病毒产品无法抵御恶意软件。
第二,其次,人们尝试检测VirusTotal,认为那里使用的扫描引擎反映了真实的防病毒产品。如果他们对检测到的文件进行了微小的更改,从而降低了VirusTotal的检测率,那么他们认为自己可以成功地规避防病毒产品。这种测试策略是有缺陷的,因为VirusTotal上的扫描引擎只支持真正产品所具有的一小部分功能,而且实际上大部分都局限于模式扫描和文件块列表,从而让人们对完整产品的实际工作方式产生错觉。VirusTotal的网站上也有说明(见下图)。

谬论2: 5%的误报率是可用的
当我在2014年写我的硕士论文时,我开发了一种基于文件异常的恶意软件检测启发式方法。我的工作基于Ange Albertini的贡献,即发现和记录文件异常,他将这些文件异常收集在他的项目Corkami中。当时作为Avira的恶意软件分析师工作的Ange,得知我的工作后来参加了我在莱比锡的硕士论文答辩。当我问他,我的启发式方法的误报率是多少是可用的时,他的回答让我吃惊。他说,零。
“零”是一个糟糕的答案,因为一旦我试图使假阳性率接近于零,检测率就会急剧下降。误报率实际上从未达到零。我对我的测试使用了49,814个干净样本和103,275个恶意样本。图片在右侧显示了误报(十字形)和真阳性(黑色正方形)率的图表。例如,在8.81%的误报率下,真阳性检测率为98.47%。这意味着8.81%的干净文件被错误地认为是恶意软件,而1.53%的恶意软件不能被检测到。即使将误报率保持尽可能低,仍有0.17%的干净文件得到了错误的判决。这样带来了巨大的弊端,导致恶意文件的检出率降低37.80%。
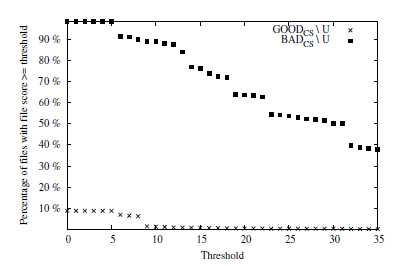
当时我并未意识到为什么误报率必须是零,当然,一定的错误率是可以接受的?防病毒产品毕竟不是完美的。每个人都听说过甚至可能遇到过防病毒产品的误报。现在我是一名恶意软件分析师,我知道了答案:是的,假阳性是防病毒产品的一部分,但可接受的假阳性率远低于你的想象。
当前的恶意软件检测研究论文通常对可接受的假阳性率有相同的误解。他们中的许多人认为,干净文件和恶意软件文件的数量大致相等,也就是说是平衡的。实际上,计算机系统很少看到任何恶意软件,但大部分时间都会处理干净的文件。例如:对于Windows 10 C:\Windows文件夹包含大约500000个文件。如果我们假设只有5%的假阳性率,检测技术将确定25000个文件为恶意文件。除非您准备好打赌,在从C:/Windows中删除25000个任意文件后,您的系统仍能正常工作,否则这是一个不可接受的数字。您准备下注多少文件?
这种对不平衡问题的误解有一个名字:基本利率谬误。这是如此普遍,以至于进行了几项研究以提高认识。Jan Brabec和Lukas Machlica总结道:“我们遇到了大量的近期论文,其中使用了不恰当的评估方法”和“糟糕的做法可能会使结果严重偏向于不恰当的算法”。研究《计算机安全中机器学习的注意事项》在十年中发表的30篇论文中检查了常见的陷阱。这些论文中有11篇受到了基本利率谬误的困扰。
然而,可以接受的误报率率到底是多少?Stefan Axelsson就侵检测的这场景下分析了这个问题。Axelsson表示“限制入侵检测系统性能的因素不是将行为正确识别为入侵行为的能力,而是其抑制错误警报的能力”,并得出结论“入侵检测系统每次事件的误报率必须低于1/100,000,即0.001%。误报率更高的解决方案不仅为负责安全的运维人员带来了更多的工作,而且还变成了“狼来了谎言”——没人再把它们当回事了。
一个可行的误报率对于能够自动响应入侵威胁的防病毒产品来说必须更低。与入侵检测系统相反,自动预防中的误报可以摧毁整个系统或中断生产流程。对于使用小于100,000个样本的干净样本集的研究工作,误报率实际上必须为零。
防病毒产品是怎么做的
现在,我们知道一个防病毒程序的误报率必须多么低才能保持可用,显然这就是为什么启发式检测不再那么简单。很多人可以想到启发式检测的思路,例如,为了检测勒索软件,只需要检查一次性重命名大量文件并因加密而提高熵值的程序。但是当这些启发式被实际应用时,你会发现有多少合法程序显示出类似的行为。以勒索软件启发式为例,例如,备份程序也做着相同的事情:批量重命名个人文件并通过压缩提高它们的熵值。
防病毒产品通过分层防御机制来解决这个问题,各种检测手段堆叠在一起以实现最佳覆盖。它们中的一些可能只能检测20%的样本,因为它们特定于某些类型的攻击或环境,例如,文件格式,行为或其他是先决条件的属性。但是,如果某些样本在其他层并没有被检测到,那么当前层依然会进行检测和处理。
大多数人可能都熟悉瑞士奶酪防御模型,其中的含义在这里很有意义。
理解了瑞士奶酪防御模型就可以理解为什么误报比漏报要糟糕的多,未检测到的恶意软件可以最终被其他层检测到。因此,单个图层的低检测率没有关系,只要其他层填补了这个空缺。但对于误报,没有类似的层层网络。但是你可能会问 “白名单呢”?。
虽然白名单机制是一定存在,但是它必须被视为最后的手段,并谨慎使用,主要有如下原因:
- 首先,白名单列表可能为恶意软件逃避杀毒软件检测敞开大门。如果程序的证书、关键字、行为或其他特征被用于允许列表,恶意软件也可以滥用它们。出于同样的原因,某些程序不能被加入白名单,例如,它们是合法和恶意文件都能使用的执行环境的一部分;或者因为它们只在某些上下文中是干净的。这类程序比比皆是,例如,远程访问工具在实际提供帮助时是可以的,但如果被攻击者静默安装,则不那么好。
- 第二,其次,合法程序每天都在演变和出现新版本或类似程序。因此,仅针对特定版本的白名单条目不是一个长期解决方案。为了调整易产生误报的检测启发式算法,几乎肯定要定期添加其他允许列表条目,这是一项维护量很大的工作。
通常,预防层的误报就是整个产品的误报,相比之下,漏报可以随意高,只要恶意代码检测层的性能能够及时的覆盖掉新出现的恶意软件即可。
重点
启发式恶意代码检测看起来非常简单,但实际上是很棘手的。虽然许多人认为高的恶意软件检出率是主要目标,但低误报率是检测启发式检测质量的最重要指标。误报率的影响常常由于基本利率谬误所被低估。
在杀软产品上,误报必须是可管理的,相应的容忍率肯定要低于0.001%。单个技术的误漏率不是那么重要,只要启发式检测覆盖了瑞士奶酪防御模型中的一些洞即可。
我希望检测技术研究能够专门关注难以检测的样本,并找到实际解决方案,而不是试图创造我们德国人称之为“会下蛋,会生产乳汁的绵羊”。永远不会有一种技术可以统治所有技术。
我也希望记者和安全影响者理解抗病毒技术的状态和检测研究的实际价值,以便他们停止加强这种误解。抗病毒营销也是一样,过时的检测技术的神话可能很好地诋毁竞争对手,但长期来看对抗病毒行业产生了不利影响。
参考文献
[ange] Ange Albertini, Corkami, Google Code project, https://code.google.com/archive/p/corkami/ now moved to https://github.com/corkami
[arp20] Daniel Arp et al, 2020, Dos and Don’ts of Machine Learning in Computer Security, https://www.researchgate.net/publication/344757244_Dos_and_Don'ts_of_Machine_Learning_in_Computer_Security
[art3] https://slate.com/technology/2017/02/why-you-cant-depend-on-antivirus-software-anymore.html
[axelsson00] Stefan Axelsson, 2000, The Base-Rate Fallacy and the Difficulty of Intrusion Detection, https://dl.acm.org/doi/pdf/10.1145/357830.357849
[bramac18] Jan Brabec and Lukas Machlica, 2018, Bad practices in evaluation methodology relevant to class-imbalanced problems, https://arxiv.org/abs/1812.01388
[cohen84] Fred Cohen, 1984, Prevention of Computer Viruses, https://web.eecs.umich.edu/~aprakash/eecs588/handouts/cohen-viruses.html
[hahn14] Karsten Philipp Boris Hahn (previously Katja Hahn), 2014, Robust Static Analysis of Portable Executable Malware, https://www.researchgate.net/publication/350722779_Robust_Static_Analysis_of_Portable_Executable_Malware
[szor05] Péter Szőr, February 2005, The Art of Computer Virus Research and Defense, Addison Wesley Professional